Hidden Technical Debt of AI Systems: Agent Harness
If you have been building agentic products in the last twelve months, you have been writing harness code: system prompts, tool wrappers, planner-executor loops, retry policies, context compaction strategies, allowlists for which tools an agent can call from which surface, judges for when to stop, and fallbacks for when the model wanders. Even drawing workflows in no-code or low-code tools like n8n is harness work. Every team has built some of this. The good teams have built a lot of it. The bitter part is that almost all of it is going to dissolve into the next generation of models, and the teams who treat their harness as a permanent product surface are going to spend a year ripping it out.
In the previous post about hidden technical debts of AI systems, we went through designs of agent runtimes – where AI agents work – and the requirements of experimentation/evaluation and providing runtimes for agents to work in production. This post is about the AI agent itself, the ongoing research and discussions of this abstraction, and it being the technical debt that most are not aware and budgeting for.
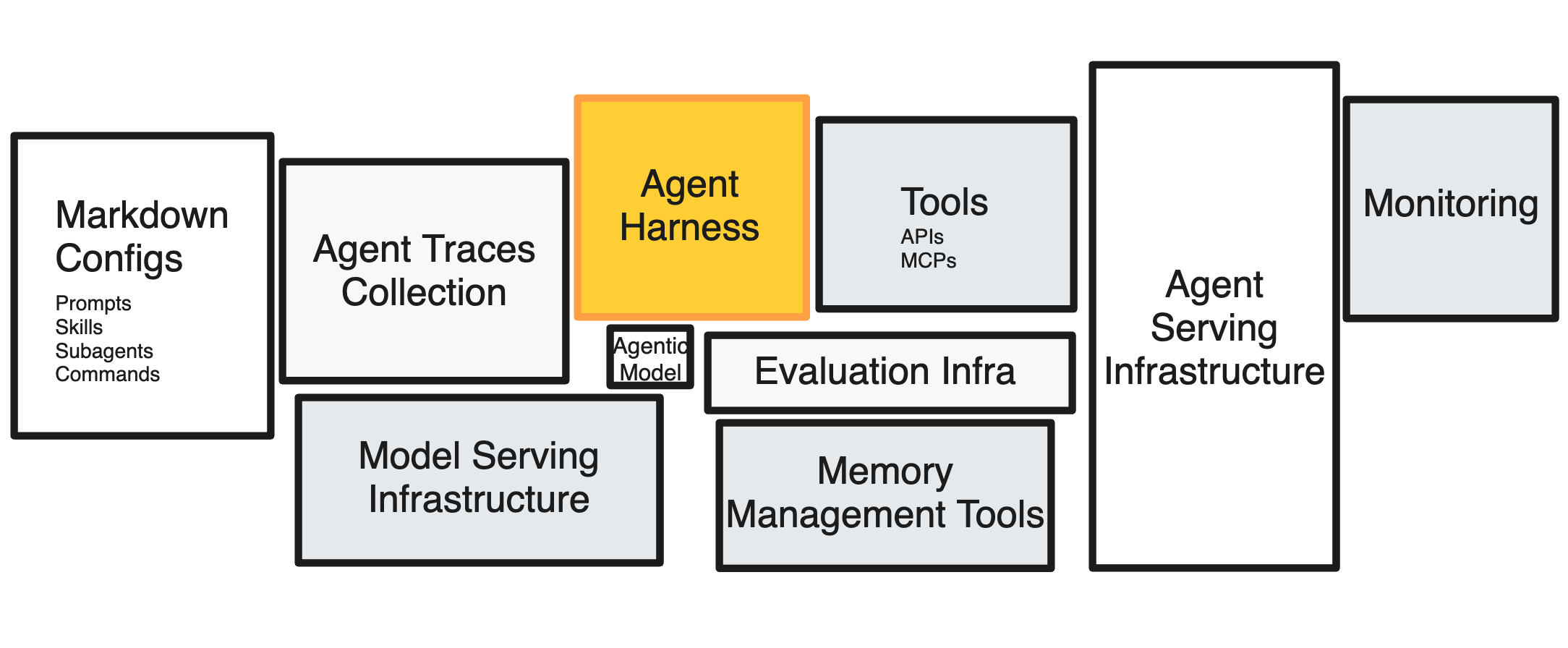
This is the third installment of a small series. The first post defined the RL environment as a five-tuple $(T, H, V, S, C)$ — tasks, harness, verifier, state, configuration — and pointed at the harness as the thing that controls how the model interacts with everything else. The second post zoomed out to the runtime and the sandbox primitives underneath. This post zooms back in on $H$ and asks the question that has been sitting unasked across all the harness-engineering blog posts of the last six months: which parts of this thing are load-bearing, and which parts are just the structure we needed at this particular level of model capability?
Agent Harness
We define agent harness as the orchestration layer that sits between the model and the environments that the model is operating in. This includes system prompts or prompts, basic sets of tools such as terminal access (bash), filesystem access (read, write), and potentially MCP client to access MCP servers that could contain tools. An agent is then a harness + a foundation model.
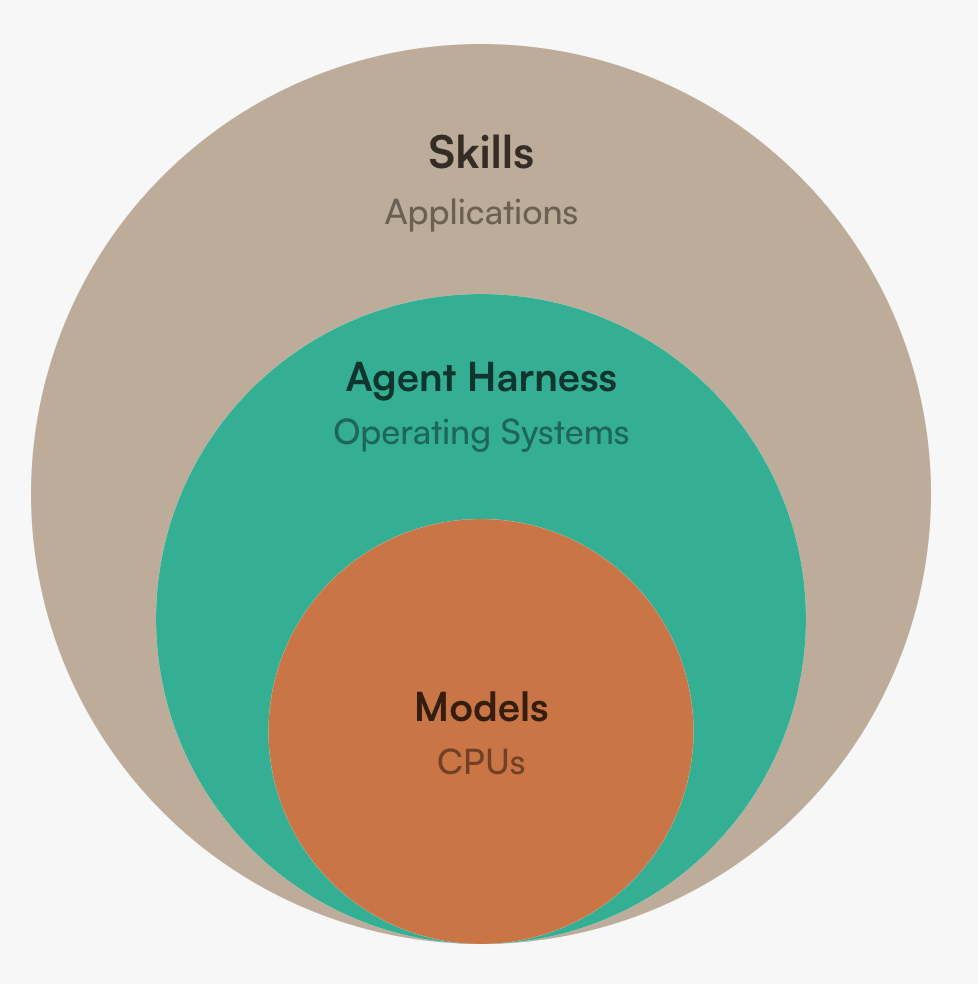
An useful analogy is treating AI as the next generation of computing. The core intelligence is contained in the model, or the CPU in a computer. And the model by it self is not useful without the operating system to orchestrate instructions and tools. The harness is the operating system. It provides interrupts and interfaces to outside world, manages different processes and threads, and manages memory (model context) to provide the end user the illusion of infinite memory and resources.
Diving in deeper with a more grainular decomposition. A harness can be an union of:
- System prompt and persona — the standing instructions that bias the model’s behavior across every turn.
- Tool surface — the set of callable functions exposed to the model, and the schemas, descriptions, and examples that teach it how to use them.
- Rollout protocol — single-turn, multi-turn, ReAct, plan-and-execute, deep-research, multi-agent. The shape of the loop the model runs inside.
- Context manager — what gets carried across turns, what gets compacted, what gets summarized, what gets dropped.
- Memory — short-term scratchpads, mid-term progress files, long-term retrievable stores.
- Sub-agent topology — orchestrator, workers, judges, sub-skills, hand-off protocols.
- Guardrails and gates — input filters, output filters, action gates, allowlists, approval tiers, KL caps in training, behavioral red lines in production.
- Verifiers and judges — the things that decide whether a step succeeded, whether a plan should continue, whether the model should stop.
- Observability — traces, replay, eval hooks, the seams the human can grab to understand what happened.
Not all harnesses are built equal; some are very minimalistic, e.g., pi while some are full featured, e.g., Claude Code. Some focuses on local personal agents, e.g., OpenClaw, some on memory, i.e., Letta code, some on recursive long-context inference, e.g., Recursive Language Models, and some on massive multi-agent (MMA) collaboration, e.g. Gas Town. As the operating system layer of AI and agentic systems, this is exactly the same as the many flavors of linux distributions for all different imaginable use cases.
Other definitions of agent harness
Naming things is the hardest problem in computer science, and the definition of agent harnesses is no different. The abstraction is constantly evolving and companies have put out vairous definitions of agent harness. These definitions can be in two broad categories - one of which we mentioned above as the research and applied science focused. The other category is user centric definition.
Let’s use F1 racing team as an analogy. AI labs and research scientists/engineers build the engine, the agentic model that powers the car. And you need a mechanics team to build the harness and the shell of the car. And that is not enough, because you need to evaluate and optimize the race car so you actually have a chance to win the race. And a team of mechanics to opearate the system, the machine learning system engineers.
Now the star of the show. The driver. It is the user of the agentic model. The drivers might need to customize the car, his racing suit, shoes, helmets, and put differnt sponsorship stickers on his helmet, his lucky charms, etc. These are the second type of harness.
Birgitta Böckeler’s harness-engineering article draws a clean distinction. There is an inner harness that the model’s builder ships — Anthropic’s Claude Agent SDK, Cursor’s Auto, Codex’s app server. These are what we discussed previously. And there is an outer harness that the user assembles on top — AGENTS.md, MCP servers, custom skills, organization-specific code review agents. Both are harness. They evolve on different clocks and they accumulate different debt.
The OpenAI team described their internal harness work by saying that their hardest challenges had become “designing environments, feedback loops, and control systems” rather than writing application code. Anthropic’s effective harnesses for long-running agents post is a worked example: a two-prompt harness with an initializer agent that builds an init.sh, a claude-progress.txt, a structured feature list as JSON, and a coding agent that picks up the next failing feature, commits, updates the progress file, and stops. The harness is not the model. The harness is also not just plumbing. It is a deliberately designed feedback loop that turns one model call into useful work over a horizon longer than any single context window.
From research to production
The most under-discussed property of the harness is that the production harness and the training harness are not the same artifact, and increasingly should not be.
In production, the harness is a constraint surface. The agent is acting on behalf of a user, against real systems, with real consequences. You want a tight allowlist of tools, scoped credentials, approval tiers for write actions, input and output filters on prompt injection, an idempotent retry policy, a maximum runtime, an audit log, a kill switch. Ashpreet Bedi’s systems-engineering post is right that read-only access is a tool configuration, not a system-prompt instruction. Anthropic’s harness-design notes and OpenAI’s harness-engineering post are right that environment design is now a primary engineering activity. In production, the right defaults look like a careful deployment of a powerful but fundamentally untrusted process: principle of least privilege, deny by default, observe everything.
In training and research, the harness is an exploration surface. The model is generating trajectories that the optimizer will use to shape its policy. If you allowlist tools, you are pre-deciding what the model is allowed to learn to use. If you wrap raw APIs, you are pre-deciding the abstraction the model will be rewarded for using. If you constrain the action space, you starve the optimizer of the very signal it needs to discover better strategies. The training harness should be wide where the production harness is narrow.
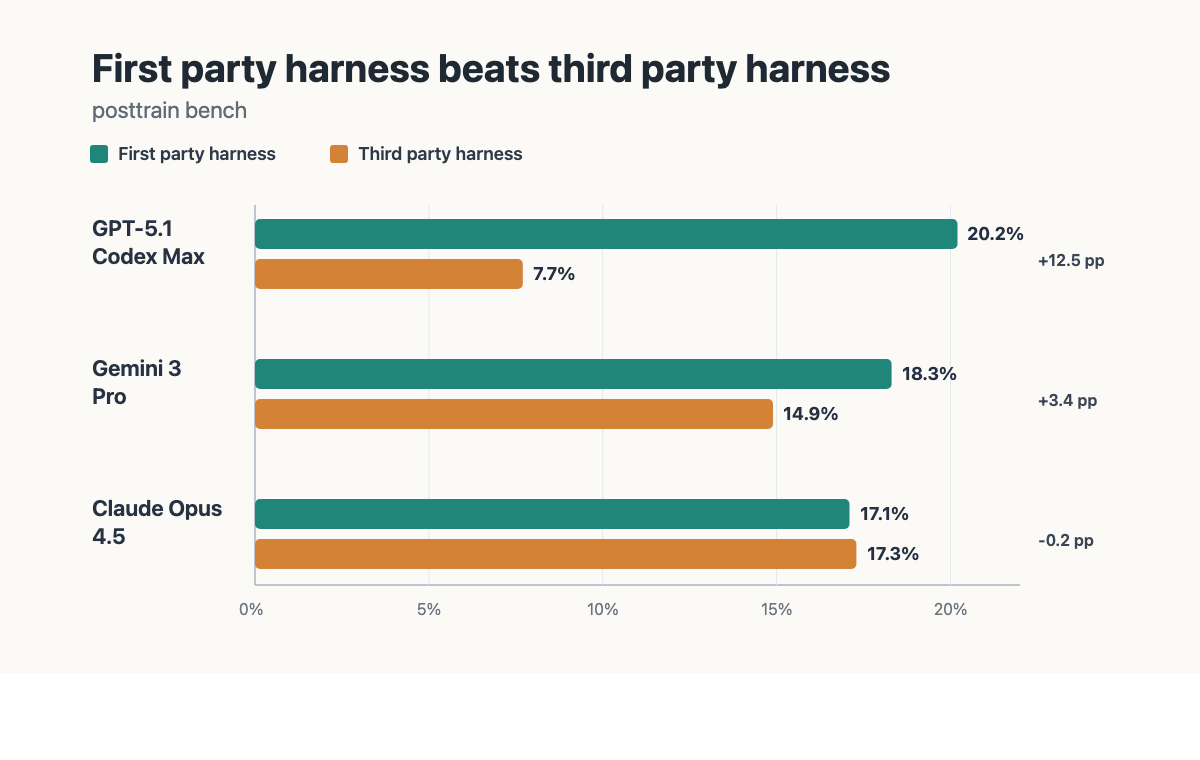
This is also the structural reason first-party harnesses outperform third-party ones on the same model. When a lab post-trains a model, it does so inside its harness — its tool schemas, its rollout protocol, its system-prompt conventions, its context layout, its stop conditions. The policy is shaped against that specific surface. The capability lives in the weights, but the way those weights get invoked is part of the training distribution. Drop the same model into a third-party harness with different tool descriptions, a different loop shape, or a different memory layout and you are running it out-of-distribution: the model is being asked to act through an interface it was never optimized against. This is why Claude inside Claude Code feels different from Claude inside a generic ReAct wrapper, and why Codex with GPT outperforms a hand-rolled scaffold on the same model. The harness is part of the contract the model was trained under which makes first party harnesses preferrable. Empirical work showed that the same model evaluated in its first party harness (1ph) versus an off-the-shelf third-party harness (3ph) shows a measurable benchmark gap, with the first-party harness consistently on top for this specific benchmark.
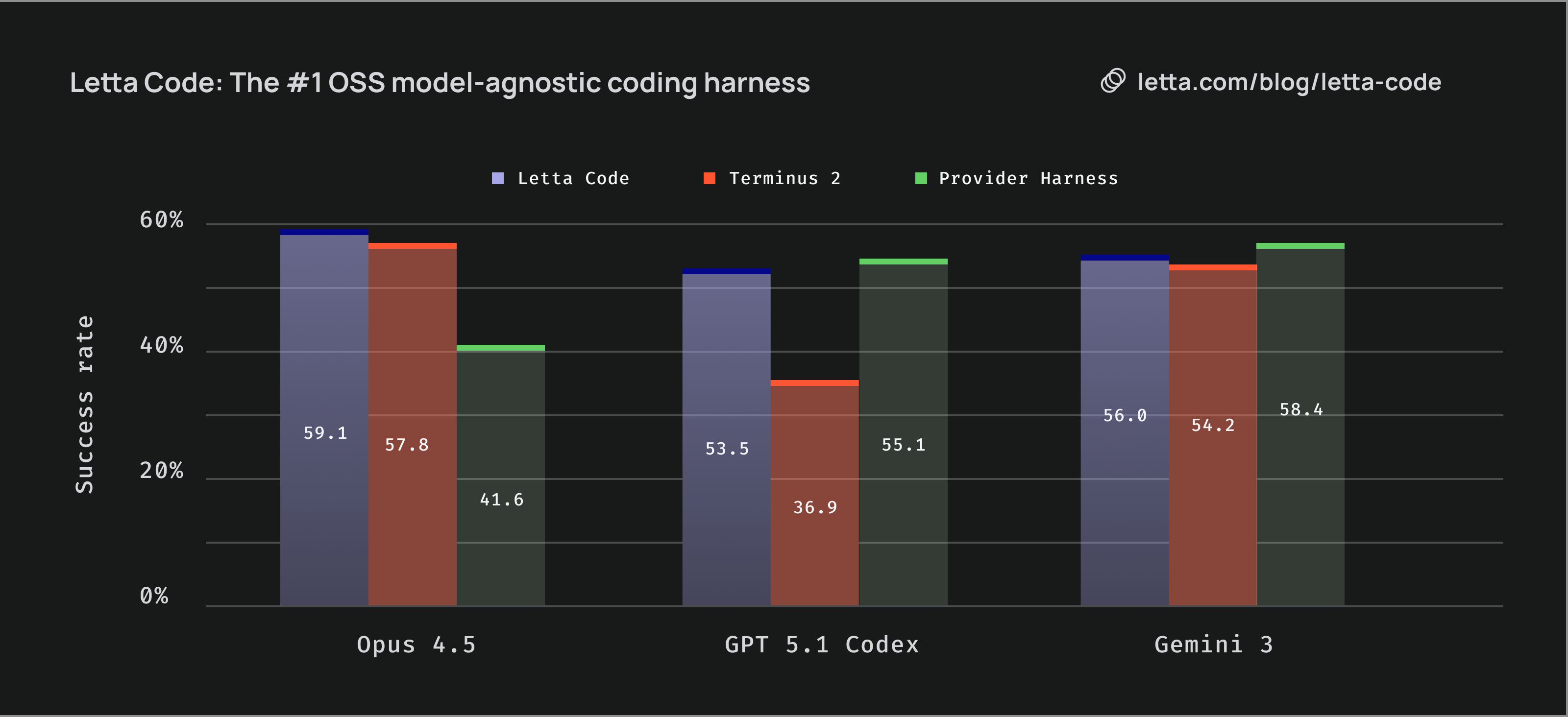
That said, the first-party advantage is not a law. A third-party harness that invests heavily in a dimension the first-party harness underweights can claim the gap back. Letta Code is the cleanest current example. On Opus 4.5, Letta Code scores 59.1% versus Claude Code’s 41.6% on their reported benchmark — a third-party harness beating the first-party one on its own model, decisively. The mechanism is exactly the one the asymmetry argument predicts: Claude Code is thin on durable memory by design, Letta is built around a memory substrate, and the benchmark rewards memory. On GPT 5.1 Codex and Gemini 3, where the first-party harnesses are stronger overall, Letta lands within a few points but does not lead. The takeaway is not that first-party always wins or always loses — it is that the harness is load-bearing, and a third-party harness with a deliberate axis of investment can outperform a first-party harness that neglects that axis.
The asymmetry, side by side:
| Dimension | Training / Research Harness | Production Harness |
|---|---|---|
| Action space | Maximal — let the model try anything that could plausibly be useful | Minimal — explicit allowlist, deny by default |
| Tools | Raw, low-level, easy to extend; agent may write its own | Wrapped, scoped, versioned, schema-validated |
| Failures | Welcome — failure is signal for the optimizer | Suppressed — fail closed, retry, page someone |
| Network | Often offline or recorded for determinism; may include adversarial perturbations | Live, with strict egress policies |
| Guardrails | KL caps, reward shaping, curriculum gates, anti-reward-hacking detectors | RBAC, JWT scoping, action gates, output filters |
| Verifier | Programmatic, scaled, often noisy on purpose | Deterministic where possible, human-in-the-loop where it matters |
| State | Forkable, snapshottable, replayable | Durable, per-user, auditable |
| Cost model | Many cheap rollouts; tail behavior matters | Few expensive sessions; latency and reliability matter |
| What “good” means | The policy improves on a held-out distribution | The user’s task succeeds without an incident |
Two specific consequences worth stating directly.
The training harness should not be a stripped-down production harness. This is path of least resistance is exactly wrong — copy the production stack, turn off the auth checks, point it at a mock database. A training harness that inherits production’s allowlists that cannot teach the model anything outside that allowlist. Microsoft’s recent post on instability in production-scale agent RL shows this point technically. Tool-conditioned contexts in long-running RL produce heavy-tailed importance-weight distributions that destabilize on-policy updates, and the fix is in the training harness, not in the production guardrails. This include KL caps, slice-by-mode diagnostics, failure-aware curricula. The training harness is itself an object of careful engineering, distinct from production.
The production harness should not be a deployed training harness. This is the more common mistake. A team builds an open-ended research environment to explore capabilities, gets impressive demos, then ships the demo. The agent acts on real customer data with no allowlist. The first time a prompt-injection payload flows through a tool output, the agent dutifully exfiltrates secrets because nothing in the harness told it not to. The training harness was wide on purpose; the production harness has to be narrow on purpose. They are different artifacts.
The bridge between research and production is the evaluation and alignment team; an evaluation harness that mirrors production tightly enough to catch behavioral regressions, run by the same team that owns the production prompts and tools. Leading AI companies structured teams that catches “did the agent changes behavior” lives between research and product, owns the system-prompt pipeline, and is graded on parity. It is a third artifact whose job is to make sure that their agents do not diverge in behaviors between harness releases and model updates and to ensure research and production alignment.
Aligning From the Inside Out, Not Shackling From the Outside
The deeper reason the production-vs-training asymmetry matters is alignment.
When you build a production harness, you are using software engineering to constrain model behavior from the outside. Allowlists, action gates, output filters, kill switches. These are necessary and they are not where alignment actually comes from. Each one of them is a fence around behavior that has not been shaped, and a sufficiently capable agent will eventually find a configuration where the fence is wrong — a tool that should have been blocked but was not, an output filter that misclassifies, an allowlist that was correct on Monday and obsolete on Wednesday because the product changed.
When you build a training harness, you are doing something different. You are letting the model explore the action space, observing what behaviors emerge, and shaping them with rewards. If the model learns to call a destructive tool inappropriately, the answer is not to add a software guardrail; it is to penalize the trajectory and let the policy update. The fence moves from outside the model to inside the model. This is alignment from the inside out. It is also the only kind of alignment that scales with capability, because every external fence has a fixed cleverness budget and the model’s intelligence is growing faster than software gymnastics.
Junyang Lin’s framing described this phenomenon. In the agent era the competitive edge moves from training algorithms to environments. Better environment produce models with better internal policies. Models with better internal policies need fewer external scaffolds in production. The teams that invest in the training harness are buying down their production-harness debt, two or three model generations out.
The two failure modes here are symmetrical and worth naming.
Over-shackling in training. A team imports its production allowlist into training “for safety,” runs RL, and produces a model that is well-behaved inside that allowlist and useless outside it. The model never learned to recover from a tool error because the production harness retried for it. It never learned to choose between two competing tools because the production harness routed for it. It never learned to stop because the production harness timed out for it. Worth being explicit: the production guardrails were doing the agent’s thinking, and the policy never had to grow that thinking.
Under-fencing in production. The opposite team trains a wide-open agent, watches it solve impressive tasks in development, and ships it with the same open harness against real systems. The agent is capable and unaligned at the surface. Prompt injection lands. Sensitive operations execute. The team patches with a stack of post-hoc filters, each one a piece of software engineering trying to substitute for shaping that should have happened in training.
The right shape, stated as a rule: the harness should be widest where the model is being trained, and narrowest where the model is being deployed, and the gap between them should be a deliberate, audited engineering artifact rather than an accident.
As model gets smarter, structure matters less
The progress of the last three years is the amount of hand-designed hard-coded orchestration logic in the harness retreating slowly into the model.
In 2023 we built RAG pipelines because models had small context windows and weak retrieval, and the harness held the entire memory layer — chunkers, embedders, vector stores, rerankers, query rewriters, citation checkers. The model was a passive consumer at the end of a conveyor belt. Most of the engineering effort was in the conveyor belt.
In 2024 we built workflows because models could not reliably call tools in a loop. Lance Martin’s account of building open-deep-research is the clearest version of this story I have read. The first version was an orchestrator-worker workflow where an LLM call decomposed a research request into report sections, parallel workers researched and wrote each section, and a final step concatenated the output. There was no tool calling because tool calling was unreliable. There was no flexible plan because flexible planning was unreliable. The harness was the structure that let a 2024 model do something useful, by working around its 2024 limitations.
By late 2024 and early 2025 the model could call tools. In winter 2024, MCP had given the ecosystem a shared interface for tools. By early 2025, Claude 3.7 and the o-series and DeepSeek-R1 had made interleaved reasoning and tool use part of the model’s native behavior. Junyang Lin from the Qwen team labelled the shift cleanly: the era of reasoning thinking, where the model thought longer in isolation, is being replaced by the era of agentic thinking, where the model thinks in order to act, observes the result, and revises. The model now decides when to plan, when to call a tool, when to stop, when to ask. Each of those decisions used to be a piece of code in the harness.
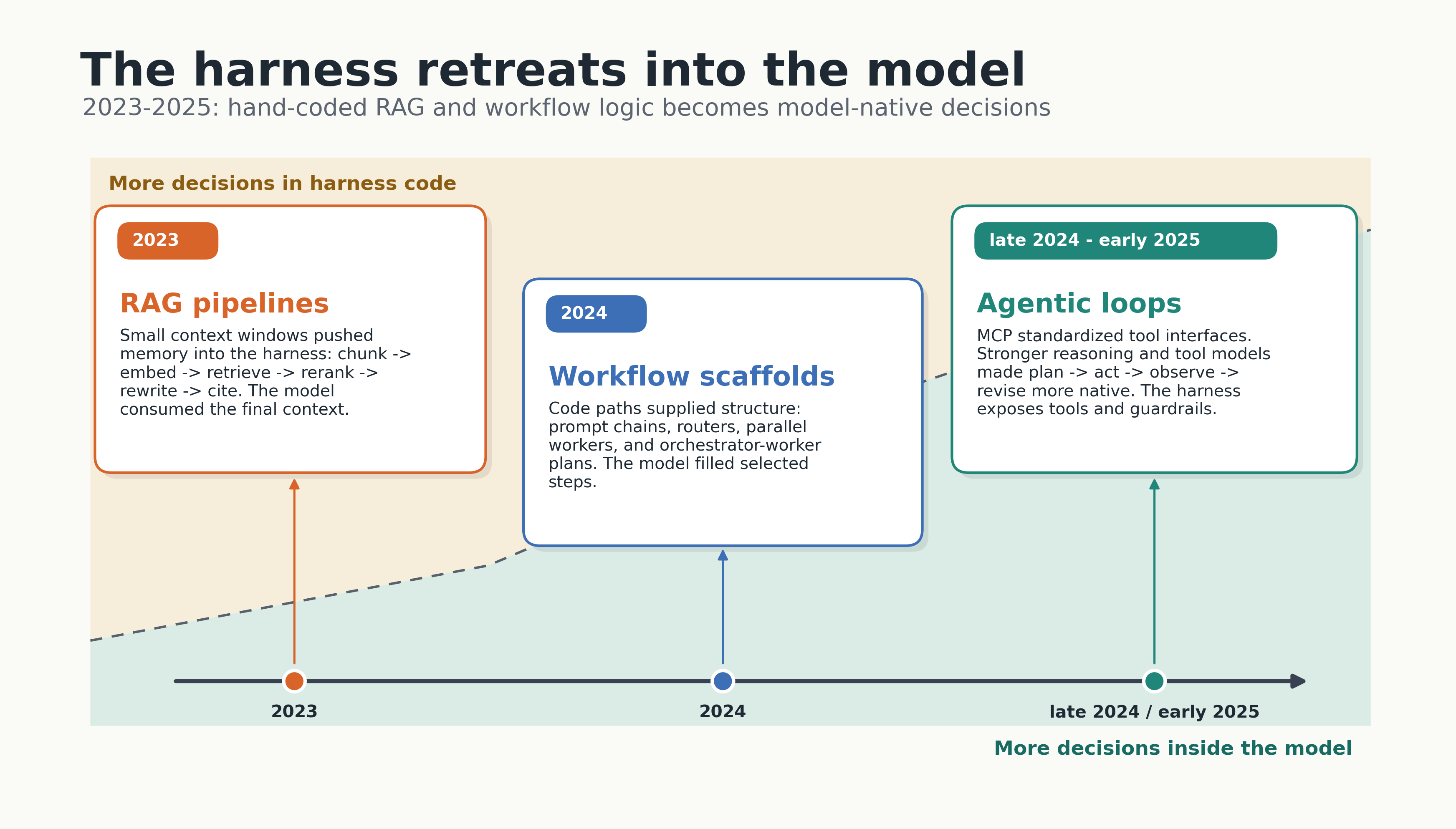
Lance’s second pass on open-deep-research is the lesson. He moved to a multi-agent system, kept the assumption that each sub-agent would write its own report section in parallel, and ran straight into the failure mode Walden Yan at Cognition warned about: sub-agents do not communicate well, parallel writes produce disjoint reports. The structure he had added in 2024 to compensate for unreliable tools was still there in 2025 even though the underlying problem had gone away. He removed it. Writing moved to a single final step. The system improved.
Hyung Won Chung from Meta puts the pattern in one line:
add structure for the level of compute you have, then remove it, because the structure becomes the bottleneck for the next level of compute.
He was talking about model architectures, not agent harnesses, but it applies here unchanged. The chunked retriever was right for 2023’s context windows. The orchestrator-worker workflow was right for 2024’s tool-calling reliability. Each generation of model exposes the structure of the previous generation as overhead.
The Bitter Lesson for agent harness
The original Bitter Lesson is Rich Sutton’s argument that, across seventy years of AI research, methods that leverage general computation have always eventually beaten methods that encode human cleverness about how a problem should be solved. SIFT lost to ConvNets. Rule-based parsers lost to neural ones. Hand-crafted chess heuristics lost to AlphaZero. The pattern is not that engineering is useless; it is that the engineering shifts. Useful engineering moves to the substrate that scales. Engineering that encodes assumptions about what the model needs gets eaten by the next round of model improvements.
We are now watching this happen to the agent harness in real time. A few examples worth being specific about.
No-code workflow builders are dissolving. The 2024 canvas tools, such as n8n its peers, sold non-engineers the illusion of robustness: a visual workflow you can see, version, and rerun. What they actually delivered was repeatability of steps, not quality of output. A semiconductor fab can run the same recipe a million times and still have yield problems; a deterministic process does not imply deterministic results the moment any node contains an LLM, and compounding error gets ugly fast past a handful of nodes. By 2026 a single long-horizon agent does what those canvases tried to assemble out of dozens of nodes, with the loop running inside the model rather than around it.

Tool wrappers are dissolving. In 2024 every team wrapped raw APIs in cleaner, more LLM-friendly tool schemas. By late 2025 the model could read OpenAPI specs. The argument Gregor Zunic at Browser Use is making is sharper still: do not wrap Chrome’s DevTools Protocol either, because the model has read ten thousand DOM bug threads and CDP examples and can write the helper it needs the moment it discovers the helper is missing. His ~600-line harness is a helpers.py the agent edits, a daemon.py keeping the websocket alive, a SKILL.md, and a run.py. When upload_file() is missing, the agent reads helpers.py, writes upload_file() using DOM.setFileInputFiles, and proceeds. The harness shrinks; the model fills the gap.
Planner-executor scaffolds are dissolving. In 2024 the standard pattern was an explicit planner LLM call producing a plan, an executor LLM call running each step, and a separate reflection LLM call updating the plan. By 2026 a single agentic-thinking model interleaves planning, action, and reflection inside its own trace. The decomposition is happening inside the model, not inside our Python.
Memory layers are dissolving. Long-running agent memory was, until recently, a complicated stack of vector stores, summarization passes, and selective retrieval. Anthropic’s long-running agent harness uses a JSON feature list, a progress file, and git log. That is intentional. Plain text in the working directory is something the model already knows how to read, write, and reason about; a custom memory abstraction is something we have to teach it about every release.
Multi-agent topologies are dissolving. Cognition’s “don’t build multi-agents” argument and Anthropic’s effective-harness post point in the same direction: the multi-agent architectures we built to compensate for short context windows and weak tool use look increasingly like overhead now that the underlying constraints have eased. Sub-agents will probably stick around for true parallelism and for context isolation, but the elaborate orchestrator-router-judge-critic graphs we drew on whiteboards in 2024 are not going to age well.
This is what makes the harness a Bitter Lesson moment. The harness is the structure we need for the level of model capability we have today. A well-engineered 2026 harness is a 2026 artifact. The teams that internalize this design their harness so the structure can come out as easily as it went in. The teams that do not are building load-bearing scaffolding around a model that is about to outgrow it. This is why modern evaluation frameworks like harbor framework and benchflow provides flexible interfaces to swap between different harnesses.
Three Optimization Surfaces
If the harness is a 2026 artifact, the next question is where to spend optimization budget. The layered framing that has aged best is: model + harness = agent, and agent + skills = product. This gives three nested surfaces, each with a different cost and iteration cadence.
| Surface | Cost to change | Iteration cadence | Owned by |
|---|---|---|---|
| Skills / prompts | Cheap — text edits, no recompile | Hourly to daily | Product builders |
| Harness | Medium — code, ships with the binary | Daily to weekly | Research engineers / Applied AI |
| Model | Expensive — post-training compute | Quarterly, lab-side | Research engineers |
The cheapest surface is skills and prompts. The most expensive is the model. The harness sits in the middle. It’s code, so it iterates faster than the model and slower than a prompt edit.
A growing line of research tries to automate the harness layer the way DSPy automated prompts. Meta-Harness-style outer-loop optimizers and AutoHarness-style agent-synthesized code harnesses share a structure: treat the harness as a search space, use the model as both subject and signal, and let an outer optimizer evolve tool wrappers, prompt scaffolds, judges, and rollout protocols. On a fixed task distribution these methods do work — the optimized harness beats hand-built defaults on the held-out slice it was tuned against.
Two caveats are worth being direct about.
First, these optimizations are local. The optimized harness is overfit to its training distribution. Move it to a neighboring task and it underperforms a generic harness; what was learned was not generalization but task-specific compensation for the model’s current weak spots. This is the Bitter Lesson failure mode one level up — structure that fits 2026 capability against 2026 tasks is exactly what the next model release dissolves.
Second, auto-optimized harnesses widen the train/prod gap. The lab post-trained the model in its harness. The auto-optimizer evolved yours against your tasks. The two surfaces now disagree about how the model should be invoked, and there is no human-readable audit trail for the disagreement because nobody wrote the resulting structure. You inherit train/prod skew with extra steps and less interpretability — a worse position than either the first-party harness or a deliberately thin hand-built one.
The opinionated direction, and the one the thin harness, fat skills ethos articulates cleanly: push the work onto the cheapest optimization surface. Keep the harness thin, with a small, deliberately under-specified set of primitives that mirrors what the lab post-trained against. Put domain expertise into skills, where iteration is fast, the artifact is human-readable, and the cost of being wrong is a text edit rather than a release. Let the lab own the model layer; that is the work they are uniquely positioned to do, and the layer where compute beats cleverness most decisively.
Automated harness optimization is a legitimate research direction. However, shipping an auto-optimized or bespoke harness into production is tech debt accumulation, because the speedup you get on today’s task distribution is being paid for in skew, opacity, and obsolescence on the next model release. A thin harness with fat skills loses a few benchmark points on niche tasks and wins everywhere the distribution shifts. And that happen most of the time if you are building a product rather than chasing SOTA benchmark leaderboard.
What the Harness Looks Like When the Model Is Smarter Than the Engineer
A useful exercise is to ask, for each piece of harness in your system, what happens if the model gets meaningfully smarter next quarter.
- The system prompt that says “always think step by step” — does anything happen if the model already does?
- The tool wrapper that converts a clean API into a “more LLM-friendly” interface — is the model now better at the clean API than at your wrapper?
- The orchestrator-router-judge graph that decomposes the task — does the next model just do this in one trace?
- The memory abstraction with embeddings and rerankers — is plain text in
progress.mdplusgit logenough now? - The output validator that catches malformed JSON — does the new model just produce valid JSON?
For each piece, ask one more question: when this piece becomes obsolete, how hard is it to remove? If the answer is “an hour,” you have an option. If the answer is “a week,” you have a debt.
This is the operational form of Hyung Won Chung’s rule. The structure is fine; the structure is necessary; the structure should be removable. Lance Martin puts the same point as a design principle: stick to low-level building blocks rather than high-level frameworks, because the building blocks let you re-shape the harness as the model shifts under you. The teams I have watched ship the most durable agent products in 2025 and 2026 are the teams that treat their harness like a 90-day artifact rather than a permanent product surface. They expect to delete most of it on a model release boundary, and they organize their code so they can.
The browser-use team’s self-healing harness is the limit case of this idea. Most of the harness is code the agent itself can edit at runtime, plus a SKILL.md telling it how. When a helper is missing, the agent writes the helper. When a helper is wrong, the agent fixes it. The harness becomes a starting point, not a frozen surface — the engineer’s job is to seed the substrate, not to anticipate every action the model will need.
What This Implies for the Next Two Years
We had very fat harnesses because models were weak in many ways. They could not use tools reliably, had tiny context windows, little reasoning, no interleaved planning, and short horizons. Every weakness bought a category of harness gymnastics that we had to do: wrappers, workflows, memory stacks, planner-executor graphs. All of those are now nearly resolved. The model ate the harness.
And it will continue to do so. Multi-agent workflows and systems will soon be trained into the model, just like workflows were. What lasts is not any specific production scaffold. What lasts are the training and evaluation data, environments, tasks, and infrastructure: the durable substrate that lets you rebuild harnesses as models change. The wide training harness, the narrow production harness, and the evaluation harness that connects them should be deliberately engineered, but not mistaken for permanent product surfaces.
Thus, thin harness, fat skills. Build the durable substrate like you mean to keep it. Build each production harness like you mean to replace it. Treat application-facing scaffolding as a 90-day artifact, and organize the codebase and system so you can throw it away on a model release without flinching. Your software engineering gymnastics will be made redundant by the next model.
The runtime is the bill nobody is budgeting for. The harness is the bill nobody is budgeting for correctly. Most teams ship it too fat, without thinking about the important data and evaluation infrastructures. The teams that flip that ratio are the ones whose agents still work when the next model lands.
References
- Sutton, R. (2019). The Bitter Lesson. http://www.incompleteideas.net/IncIdeas/BitterLesson.html
- Martin, L. (2025). Learning the Bitter Lesson. https://rlancemartin.github.io/2025/07/30/bitter_lesson/
- Chung, H. W. (2024). Don’t teach. Incentivize. https://youtu.be/orDKvo8h71o
- Anthropic. (2025). Effective harnesses for long-running agents. https://www.anthropic.com/engineering/effective-harnesses-for-long-running-agents
- Anthropic. (2024). Building effective agents. https://www.anthropic.com/engineering/building-effective-agents
- Anthropic. Claude 4 prompting guide — multi-context window workflows. https://docs.claude.com/en/docs/build-with-claude/prompt-engineering/claude-4-best-practices
- Lopopolo, R. (2026). Harness engineering: leveraging Codex in an agent-first world. OpenAI. https://openai.com/index/harness-engineering/
- LangChain. (2025). The anatomy of an agent harness. https://blog.langchain.com/the-anatomy-of-an-agent-harness/
- Yan, W. (2025). Don’t build multi-agents. Cognition. https://cognition.ai/blog/dont-build-multi-agents
- Cognition. (2026). What we learned building cloud agents. https://cognition.ai/blog/what-we-learned-building-cloud-agents
- Zunic, G. (2026). The Bitter Lesson of Agent Harnesses. Browser Use. https://browser-use.com/posts/bitter-lesson-agent-harnesses
- Zunic, G. (2025). The Bitter Lesson of Agent Frameworks. Browser Use. https://browser-use.com/posts/bitter-lesson-agent-frameworks
- Yutori. (2025). The bitter lesson for web agents. https://yutori.com/blog/the-bitter-lesson-for-web-agents
- Böckeler, B. (2026). Harness engineering for coding agent users. martinfowler.com. https://martinfowler.com/articles/harness-engineering.html
- Lin, J. (2026). From “Reasoning” Thinking to “Agentic” Thinking. https://x.com/JustinLin610/status/2037116325210829168
- Bedi, A. (2026). Systems Engineering: Building Agentic Software That Works. https://x.com/ashpreetbedi/status/2041568919085854847
- Microsoft. (2025). Diagnosing instability in production-scale agent reinforcement learning. https://devblogs.microsoft.com/engineering-at-microsoft/diagnosing-instability-in-production-scale-agent-rl/
- Post-training harness mismatch and benchmark performance. https://arxiv.org/abs/2603.08640v1
- Lee, Y., Nair, R., Zhang, Q., Lee, K., Khattab, O., & Finn, C. (2026). Meta-Harness: End-to-End Optimization of Model Harnesses. https://arxiv.org/abs/2603.28052
- Lou, X., Lázaro-Gredilla, M., Dedieu, A., Wendelken, C., Lehrach, W., & Murphy, K. P. (2026). AutoHarness: improving LLM agents by automatically synthesizing a code harness. https://arxiv.org/abs/2603.03329
- gbrain. Thin Harness, Fat Skills. https://github.com/garrytan/gbrain/blob/master/docs/ethos/THIN_HARNESS_FAT_SKILLS.md
- Anthropic. (2024). Model Context Protocol. https://modelcontextprotocol.io/
- Anthropic. (2025). Claude 3.7 Sonnet. https://www.anthropic.com/news/claude-3-7-sonnet
- Lee, H. (2026). A Taxonomy of RL Environments for LLM Agents. https://leehanchung.github.io/blogs/2026/03/21/rl-environments-for-llm-agents/
- Lee, H. (2026). Hidden Technical Debt of AI Systems: Agent Runtime. https://leehanchung.github.io/blogs/2026/04/24/hidden-technical-debt-agent-runtime/
@article{
leehanchung,
author = {Lee, Hanchung},
title = {Hidden Technical Debt of AI Systems: Agent Harness},
year = {2026},
month = {05},
day = {08},
howpublished = {\url{https://leehanchung.github.io}},
url = {https://leehanchung.github.io/blogs/2026/05/08/hidden-technical-debt-agent-harness/}
}