Information Trifecta
With the advent of large language models and other foundational models, the cost of generating new content is rapidly approaching zero. At one end of the spectrum, OpenAI is collaborating with Hollywood using its Sora model to create video content for studios, while companies like Suno and Udio are commoditizing music production, making it virtually cost-free. At the other end, Google DeepMind’s AlphaFold can now predict millions of protein structures, and the widespread availability of large language models (LLMs) has significantly reduced the cost of text generation. It seems we are heading towards an era where content is free and vying for our attention. Or are we?
In project management, there’s the concept of the triple constraints theory, which posits “Time, Quality, Cost - Choose Two.” We introduce an equivalent concept in the realm of information: “Novelty, Utility, Credibility - Choose Two.”
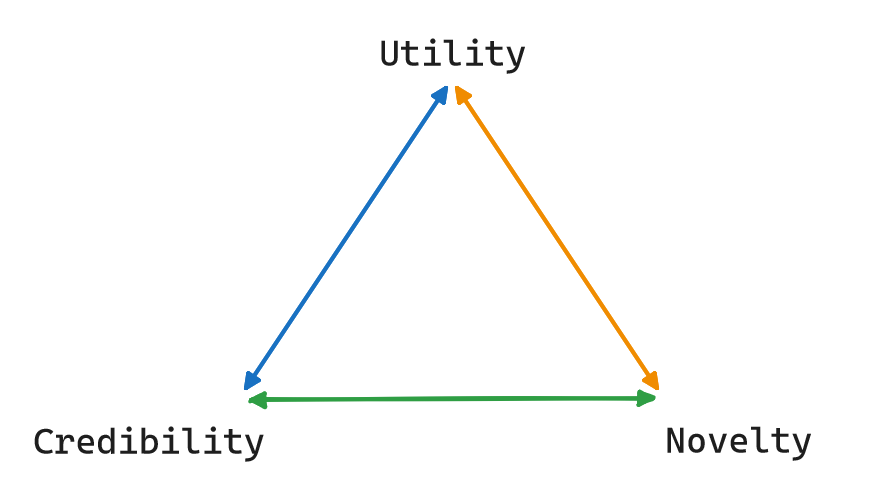
We borrow this concept from U.S. Patent Office, where patentability requires novelty and utility. The U.S. Patent Office then grants credibility. Thus, the approved patten completes the information trifecta.
How, then, do we try to achieve this trifecta for our generative AI based systems?
Chat-with-X
A retrieval-augmented generation (RAG) system works by first retrieving the relevant content from a search engine. It then use LLMs to generate content based on the retrieved content. The most common use case for this is Chat-with-X, e.g., chat with PDF, chat with support manual, chat with knowledge base, chat with a website, etc.
The RAG process lends the content credibility, backed by the search engine. From an User Experience perspective, we do then have to display the references, citations, or links to the retrieved content to provide or shift the credibility to the source of the information. This retrieved information can also be assumed to have some levels of utility, as it is retrieved based on user inputs to directly address user concerns. Though the utility is then dependent on the relevancy of the result and how user intend to utilize the information.
How, then, do we acquire novelty for the information? Should we rely on the user’s Google-fu to interrogate the system and ask novel question? Or is novelty even required?
In summary,
The system is responsible for Credibility.
The User is responsible for Utility and Novelty.
Information Discovery
Information retrieval systems, such as search engines or Google, are designed to surface relevant information. One of teh most important use case of such system is for research and information discovery.
One method to produce novelty is to fuse information from multiple different sources.

In recommendation system, the machine learning engineers cross user features with product features to produce better models. In a LLM based system, there’s a potential to do similar, to cross information from multiple sources, with the hope that we could retrieve multiple pieces of relevant information and the LLMs would be able to synthesize and fuse them to produce novelty.
Physically, we can go to the library to research on topics we wish to acquire information. Virtually, there’s the Internet, a living organism with links being created and destroyed at any instant. The research process is creative and systematic work to increase the stock of knowledge. It is crucial for tasks like legal discovery and financial due diligence. To quote Tom from the show Succession: “Information, Greg, is like a bottle of fine wine. You store it, you hoard it, you save it for a special occasion, and then you smash someone’s fuckin’ face in with it.”
These information are oftentimes hidden nuggets in a large piece of text that we do not know if it exists. This is where we reply on the information retrieval system helps to surface the unknown unknowns for novelty. Users then would have to bear the burden to ensure the sources are credible, as different sources can provide different angles of views and could have different levels of trustworthiness.
Yet, the conundrum remains that even with novelty and credibility, information might not always have utility. In the world of academia and startup worlds, this is akin to brilliant researchers inventing new technology and then searching for problems to solve. Or, in the world of finance, some individuals might possessess pieces of information but could not capitalize on the information. At the end of the day, it requires a domain expert to recognize these hidden gems to grant it utility.
In such systems, summarization or anything that reduces the fidelity and resolution of information will be an impediment to the process.
In summary,
The system is responsible for Credibility and Novelty.
The User is responsible for Utility.
Content Generation
Another common use case for generative AI is to use these models to assist in generate new creative content. These could range from texts to audio/videos. The process of these content generation is usually many iterations of content generation, caliberating based on the creativities of the end user. The end user could typically increase the creativity of the model by varing the text prompts to the model, turning up the temperature of the generation to increase variance, and sample more generated contents. With these statistical tricks, we achieve novelty.
A very good example would be the Air Head video produced by Shy Kids. They have documented their journey in this article. As opposed to what people would imagine that one prompt and a perfectly nice creative video is generated by OpenAI’s Sora, it was quite a journey for the producers of the film using Sora as a tool to assist their creative process using the human-computer interface. This expertise lends the generated content credibility.
However, this is highly dependent on the user. Some less credible users would have the opposite effect. As an example, Amazon Review spammers are very much not credible, but the generated content still have high utility for its intent and purpose.
This, then means if we are using generative AI for content generation, users have to be very thoughtful, with reviewing and iterative prompting to ensure the generated content is of high quality and utility. The users are lending their own credibility to the generated content and their own creativity to ensure utility. Turns out generating customer emails or homework solutions using ChatGPT still requires human in the loop under this framework of information trifecta.
In summary,
The system is responsible for Novelty.
The User is responsible for Credibility and Utility.
Conclusion
In this blog post, we outlined how to integrate information trifecta in designing a generative AI systems. Systems that assist users in doing so could result in a significant competitive advantage.
@article{
leehanchung,
author = {Lee, Hanchung},
title = {Subject: Information Trifecta},
year = {2024},
month = {04},
howpublished = {\url{https://leehanchung.github.io}},
url = {https://leehanchung.github.io/blogs/blog/2024/04/23/information-trifecta/}
}