How Tik-Tok Wins The Social Media Recommendation System War
ByteDance (owner and operator of Tik-Tok and TouTiao) released its recommendation system design for its TouTiao app on 2018-01-16. Here, we will try to interpret how TouTiao’s recommendation model work under the hood. Our conjecture is that ByteDance a very similar recommendation system architecture for Tik-Tok.
Distributing information algorithmically is the standard for software platforms today, such as social networks, search engines, and browsers. And at the same time it has invited scrutiny, challenges, and misunderstanding from the public. This following presentation by Cao Huanhuan aims to provide transparency to the public.

1. System Overview

A recommendation system, described in a formal way, is a function that matches users’ satification with the served content using three input variables: Xi, Xu, and Xc.
Xirepresents content, including graphics, videos, Q&As, major headlines. It’s imperative to consider how to extract characteristics of different contents to make recommendations.Xurepresents to user characterization. It includes various profiles such as interest tags, age, gender, occupation, etc, in addition to implicit user interests determined by user behavior models.Xcrepresents environment characterization. This feature is an artifact from modern mobile Internet, where users can move between different locations such as home, commuting, work, travel destinations, etc. Combining all three input variables, the model can provide an estimate of wheter the recommendated content is appropriate for the user in a given scenario.

Given the above, the question is now how to introduce implicit goals that cannot be directly measured. Click-through-rate, reading time, likes, comments, reposts, etc are all quantifiable goals. However, in large scale recommendation models, it is imperative to introduce implicit quality control goals for content moderation such as frequency of advertisement served, supression of vulgar content, supression of click-baits, promoting important news, etc. On top of encouraging users to browse more contents, the algorithm also has to encourage users to interact or contribute contents to the community.

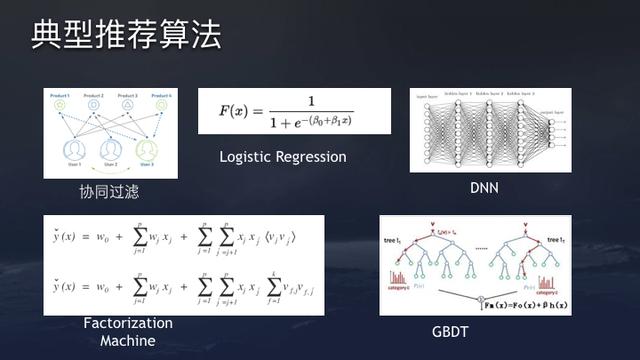
The aforementioned formula y = F(Xi, Xu, Xc) is a classic supervised learning problem. There are many methods that can be implemented such as traditional collaborative filtering models, supervised learning algorithms, logistic regression algorithms, deep learning based models, factorization machines, gradient boosted decision trees, etc.
An excellent productionized recommendation system requires a flexible model experimentation platform, which can support a combination of multiple different models, including model structure adjustments. It is popular nowadays to combine logistic regression with deep neural networks for the purpose. Facebook, for example, has combined logistic regressions with gradient boosted decision trees over the last couple of years. ByteDance today uses the same powerful recommendation models and tune them specifically for different business scenarios.
After modeling, ByteDance analyzes feature importances and found four types of significant features.
- Relevance features, which evaluate if content is relevant to the user. Explicit matching includes keyword matching, classification matching, topic matching, etc. Implicit matching includes cousine distances from user vector and content victor from factorization machines models.
- Environmental characteristics, including time and geographic information.
- Content popularity, including global popularity, category populatiry, topic popularity. This is quite useful in large scale recommenders especially for user and content cold-starts.
- Collaborative features. This helps to allieviate the problem of recommendation dead-ends. The collaborative features do not take into account the user’s existing history but instead analyzes similarity between different users through user behaviors, e.g., click similarity, interest classification similiarty, topic similiarity, etc, and therefore improves the recommendation model’s exploration capabilities.

Most of ByteDance’s recommendation systems are trained using online training, which is resource efficient and provides immediate feedbacks. This is extremely important for a data product. Changes in users’ needs and requirements can be promptly captured and reflected at the next interaction. User action streams such as click, view, bookmark, and share are collected using Apache Storm. Model serving is provided by an internal high efficiency system. Due to the rapid growth of ByteDance data, similiar data pipelining libraries cannot satisfy ByteDance’s requirement for stability and perforamnce. Thus ByteDance has developed internal tools that is suitable for its particular use case.
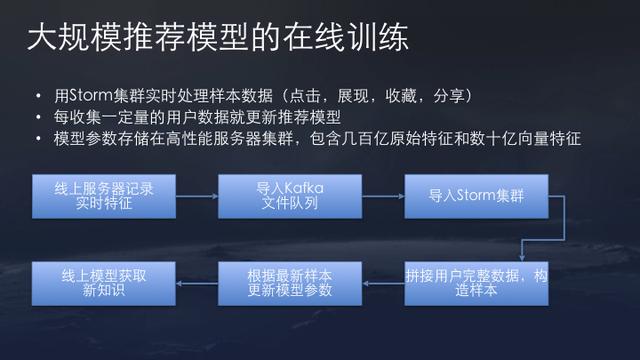
Currently, ByteDance’s recommendation is one of the largest in the world, with tens of billions raw feature vectors and billions of feature vectors. The overall machine learning pipeline goes from online server data aggregation, to Apache Kafka stream, and then processed by Apache Storm clusters. The system collect user activities as training labels and peforms online training to update the model parameters based on the latest samples.
The main delay in the pipeline is users’ activity feedback delay as users might not interact with the app right away after a new recommendation is served using a new model. Aside from this, the whole machine learning pipieline is orchestrated in real time.
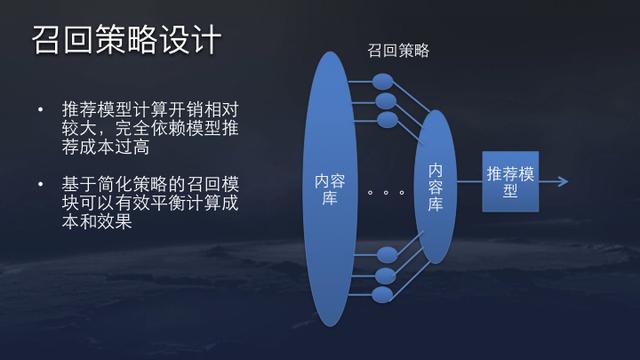
It is improbable for a recommendation system to estimate all the contents within a model due to the large amount of data handled by ByteDance, including tens of thousands types of short videos. Thus, a realistic matching strategy is to reduce the recommendation space to thousands. Due to a design requirement of 50ms inference budget, this requires a highly efficient matching strategy. Recall that an online recommendation systems has a pipeline of all items (millions) -> candidate generation/matching (hundreds) -> ranking (dozens).
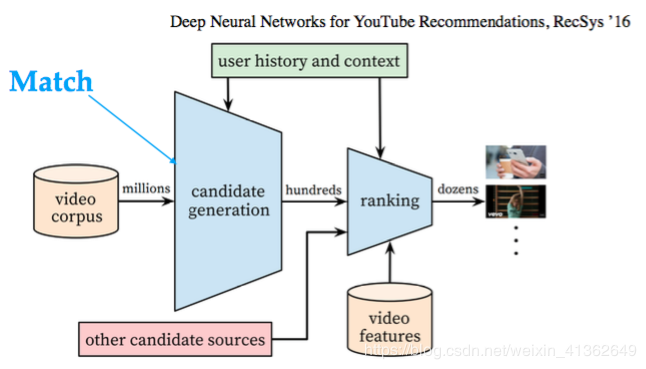
There are many strategies for implementing matching. ByteDance primarily uses MapReduce logic, with the keys being categories, topics, physical presence, sources, rankings, freshness of content, user actions, etc. Online matching should be able to rapidly reduce the content space using different keys to filter through the content library in a very efficient mannor with map reduce.
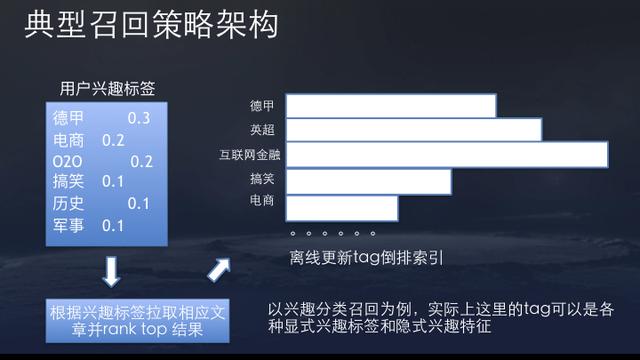
ByteDance’s system is built on the foundation of content analytics and user tags data mining. It’s recommendation engine requires user tagging and content tagging for feature extraction. In addition, its matching engine requires tagging for both user and content as well.

2. Content Analytics
Content analytics includes including text analytics, image analytics, and video analytics. The role of content analytics is for modeling and building user profile, e.g., tag an user who reads Internet articles with Internet, etc. Thus, it is essential to have tags for content, text, images, videos, etc. This presentation will mainly focuses on text analytics.

Text taggings can help recommendations directly. For example, the content of Meizu can be recommended to users who follow Meizu. This is the matching of user tags.
Users will find that, main channel recommendation might degrade after a certain period of time. In that case, they can visit some specific tags/channels such as tech or sports. And going back to the main channel, the recommendation feed will be become better. This is because the recommendation model is end to end.
Sub-channel exploration space is smaller and it is important that the sub-channels algorithms do well so they can in term improve the main channel recommendations. This also requires good content analytics.

The image above is an actual text case for TouTiao. This article has classifications, keywords, topics, and entity words as text analytics features. Earlier recommendation systems from the Amazon, Walmart, and even Netflix, were able to serve recommendations using collaborative filtering without text analytics. However, for an information product, user mostly consumes information in the same day. Without text features, it would be very difficult to solve the cold start problem for new contents and collaborative filtering features will not be able to solve the problem.
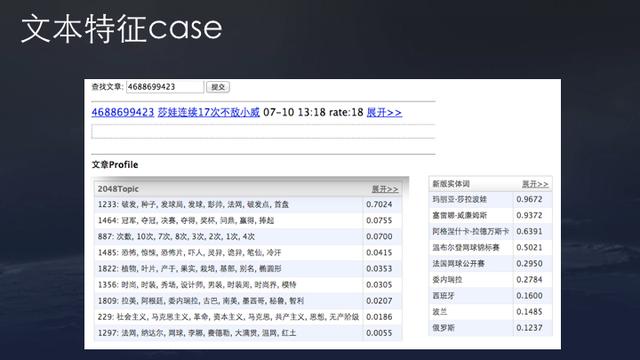
The main text features extracted by TouTiao recommendation system include the following:
- Semantic tagged features, which explicitly tags the article with semantic tags. These tags are defined by humans with clear and defined tag structures.
- Implicit semantic features, mainly topic features and keyword features. Topic features are descriptive feature about distribution of phrases, without a clear meaning. Keyword features are bsaed on some aggregated feature descriptors without an explicit set.

In addition, the text similarity feature is also very important. One of the biggest user feedback is why the recommender always repeat the similar recommendations. The difficult of that problem is that everyone’s definition of repeated content differs. For some, reading articles about Real Madrid and Barcelona in two consecutive days is a repeat, but for the dedicated fans, that is not nearly enough.
To solve this type of problem, ByteDance utilizes semantic similarity of topics, sentences, and article bodies for online learning.
Similarly, ByteDance models consider location and time features for the content’s location and timeliness. Lastly, it considers quality-related features, and determine whether the content is vulgar, pornographic, sponsored article, or click-bait?

The figure above are the semantic feature and their use cases. They have different levels and different requirements.

Every module of the process requires different granularities. Classification modules requires complete coverage for all contents and videos with low precision requirements. Entity recognition modules cares about high precision in distinguishing the person or place, but it doesn’t need to be comprehensive. Conceptual modules are responsible for solving the semantics that are more accurate and belong to abstract concepts.
In practice, it was found that these modules are all technically interoperable and ByteDance deployed an unified technical architecture.

Although currently the implicit semantic features are already used to help recommenders, the labels needs to be continously updated as the nouns and the meanings evolve. Superivised semantic language labels are still an requirements for text tagging despite the resources devoted to unsupervised semantic tagging. Semantic tags is a litmus test to check a company’s NLP technology level.
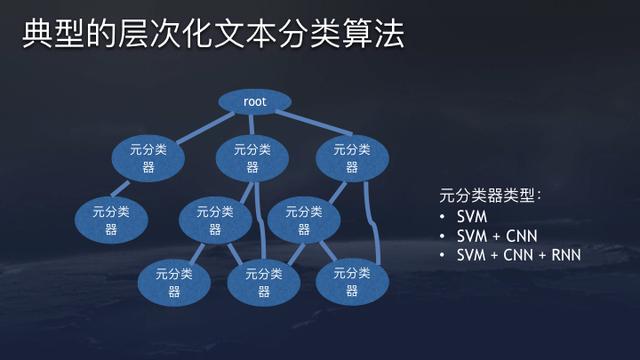
TouTiao’s recommendation system is a classic hierarchical text classification model for online classification. At Root, the first layer below is a category such as technology, sports, finance, entertainment, sports, and then subdivides football, basketball, table tennis, tennis, track and field, swimming …, and football is further subdivided into International football, Chinese football. And Chinese football is subdivided into Chinese A, Chinese Super League, national teams, etc. The use of hierarchical text classification system provides better coverage and safeguard against minority class inbalance problems versus using individual classifiers.
Except for certain exceptions, ByteDance uses skip connections, as shown in the image, to help improving recall of its models. This allows different sub-classifiers with different architectures to co-exist with each other, e.g., SVM, SVM+CNN, SVM+CNN+RNN.
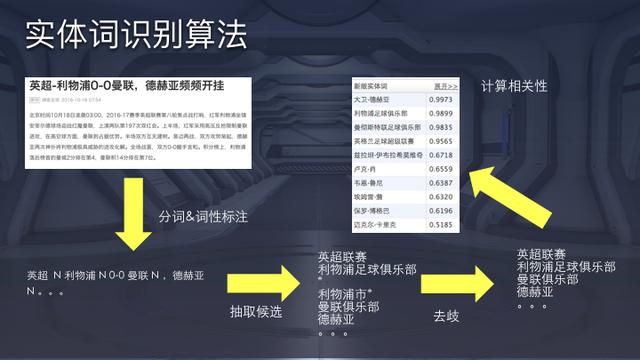
As an example, the figure above demonstrates ByteDance’s name entity recognition model. Candidates are selected based on semantic segmentations and part-of-speech tagging. Then its mapped to the knowledge bank to differentiate the actual descriptive word phrases. If, the candidates maps to a too many entities, it goes further through word vectorization, topic modeling, and phrase modeling. A correlation model is generated at the end of the process.
3. User Tagging
The two cornerstone of a recommendation system are content analytics and user tagging. User tagging is relatively a harder engineering challenge while content analytics is more of a machine learning challenge.
The common user tags that TouTiao are topics of interests to users, include categories, keywords, sources, user interest groups, and various vertical interest (automobiles, sports, stocks, etc.). In addition, there’s also information such as gender, age, and location.
Gender information can be obtained via third-party logins. Age is estimated by machine learning models through cellular phone models and user’s activities time distributions. Location comes from user authorized location information. And ByteDance can approximate the user’s locality using classical clustering algorithms. Combining user locality information with other informations, the model can then infer the user’s workplace, work travel locations, leisure travel locations, etc. These user tags are used to improve the recommendations system.

The simpliest form of user tagging is browsing history but it involves in some data preprocessing strategies, which mainly includes:
- Noise filtering. Filter out the click bait titles with high bounce rate
- Discounting top news. Discounting the weights of user interests on contents with hot reach as that signal is likely to provide little information reflective of users interests.
- Time decay. User’s interests shifts over time. So the model is designed to biased towards users current behavior. Thus, as user interactions increases, feature weights from older interactions will decay over time as feature weights from more recent interactions gets overweighted.
- Discounting unclicked articles. If a recommended article served to the user did not generate an action, the revelant features (category, keyword, source) weights will be discounted.
A the same time, the model must also consider the given priors such as whether there are too many related contents served and related app closure and user dislikes.

Data mining for user tags is relatively simple in general, involving the prior mentioned engineering challenges. The initial version of TouTiao’s user tag mining is using a batch processing approach. Aggregating user activities over the past two months and daily active users activities every single day and batch process them on a Hadoop cluster for calculation.
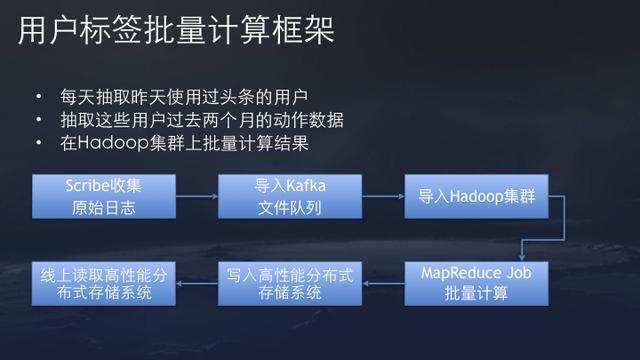
One problem ByteDance ran into is that with the rapid growth of users, the amount of compute required became extremely large for models training and batch processing tasks. In 2014, ByteDance found it can barely finish the daily the batch processing task of several million user tag updates on Hadoop clusters. The shortage of cluster computing resources starts to effect other tasks. It found theres an increasing pressure on recording data to its distributed storage systems. The lag of user interest label updates becomes longer and longer as well.

At the end of 2014 , TouTiao launched its current online user tagging Apache Storm cluster streaming computing system. After switching to a streaming data backend, user taggings are updated online as click streams come in, with a relatively small compute costs. It saves 80% of CPU time and computing resources overhead. It now only requires dozens of servers to support online update of user interests models with quasi real-time model feature updates.

ByteDance also found that not all user tags requires a streaming system. Information such as gender, age, and location does not need to be recalculated in real time; they are still updated on a daily basis.
4. Evaluation and Analysis
Now after introducing the overall architecture of ByteDance’s recommendation system, let’s look at how ByteDance evaluate the effectiveness of their system. Systems that cannot be evaluated cannot be optimized.

Effectiveness of recommendations can be impacted by a variety of factors, such as changes in the candidate set, improvements or additions to the recall module, increase in recommending features, improvements in the model architecture, optimization of algorithm parameters, etc. The significance of the evaluation is that many optimization efforts might not have positive results. We cannot simply just optimize the system, deploy online, and expect immediate improvements.

An end to end evaulation of a recommendation system requires a comprehensive evaluation platform, powerful experimentation platform, and an easy to use experiment analytics tool stack.
A comprehensive evaluation platform does not rely on a single indicator such as click rate or bounce rate, but a mixture of evaluations metrics. Over the past few years, ByteDance has been trying to synthesize an unified evaluation metric from a wide varieties of indicators and the effort is still continuing. Currently the decision of deploying a model still relies on a council of experimented team members from different departments.
The quality of a company’s models is not determined by its engineering efforts but by the quality of its experimentation platform and its data analytics tool stacks. Both would help tremendously on the confidence of the evaulation metrics produced by machine learning models.

Constructing a good evaluation platform requires following a few key principles.
- Considering both long term and short term KPIs. From the author’s e-commerce experiences, its quite often that user activities spikes in the short term due to model adjustments but those adjustments are quite ineffectual in the long term.
- Considering both user indicators and platform indicators. TouTiao, as a content creation platform, must provide value to both content creators and users, and at the same time consider the interests of advertisers. This is a process of optimization and balancing interests between multiple parties.
- Consider the collaborative filtering effects. It’s difficult to isolate traffics from different sources during an experiment, thus we need to pay attention to exogenous variables.

The advantage of a powerful experimentation platform is the capability of automatic load balancing traffics to serve multiple concurrent experiments without human intervention. In addition, it should redirect the traffics immediately after experiment finishs to reduce analytics costs, improve the speed of staggering model training, and as a result, rapidly iterating through different model optimizations.
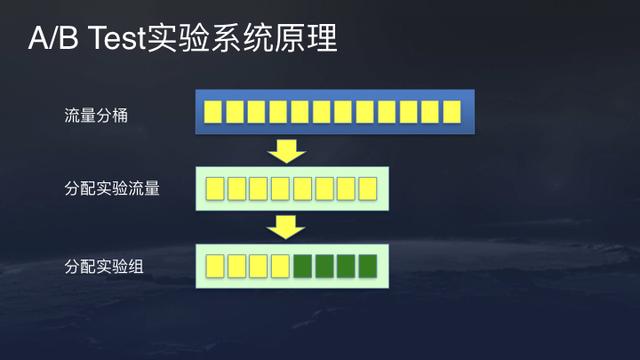
This is the basic principle of TouTiao’s A / B Testing experiment platform. First, it splits users into buckets offline, then distribute the traffics to different experiments online. It then labels the user profiles with their respective buckets and distribute them to the experimental group.
For example, ByteDance can start an experiment with 10% traffic with two experimental groups each having 5% of traffic and take another 5% of the traffic as baseline.
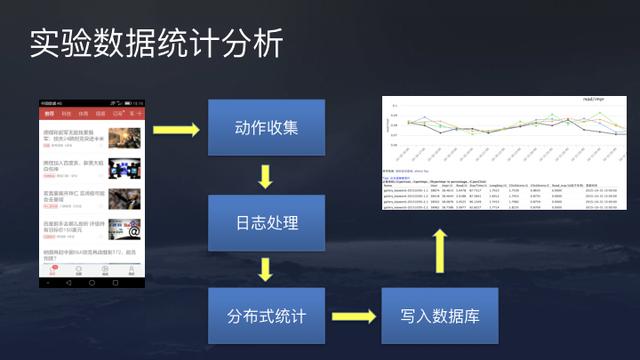
For experiment data analytics, user actions will be collected in quasi real time and can be observed every hour. But since hourly activities fluctuate during a single day, the activities data is usually analyzed on a daily basis. After data collection, it is then processed as a daily log, with distribution statics calculated. Then write the results to the database for easy visualization.

Under this system, engineers only need to set traffic flow requirements, time of experiment, define custom filters, define experiment ID, and the platform will automatically generate experiment data comparison, experiment data confidence, experiment summary, and optimization suggestions.

Even then, a powerful experiment platform is not enough. The online experiment platform can only infer changes in user experience through changes in data indicators, but there are differences between data indicators and user experience, and many indicators cannot be fully quantified. Many improvements still require manual analysis, and major improvements require manual evaluation and secondary confirmation.
5. Content Security and Social Responsibility
Lastly, here are some things that TouTiao has done for content security and social responsibility. TouTiao is now the largest content creation and distribution receipt in the country and should pay more attention to its social responsibility as the leader of the industry. A problem with 1% of the recommended content will have a tremendous impact on society.

ByteDance puts content security as its highest priority from the get go. A team of content reviewers for content security has been set in place singe the founding of the company. There were less than 40 team members who developed all clients, backends, and algorithms at the time.
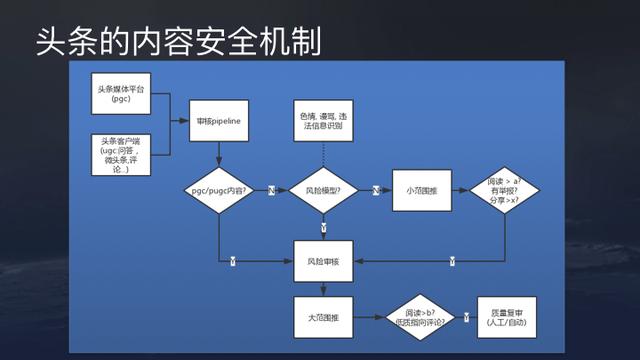
Today, TouTiao’s content mainly come from two parts.
First, there’s the professionally generated content (PGC) platform with matured content production capabilities.
Second, there’s the user generated content (UGC) platform, e.g., Q&A, user reviews, micro headlines (tweets).
Both of these platform need to pass an unified content review mechanism. For the comparatively smaller volume of PGC content, ByteDance will perform a risk review directly and wont have a wide range revamp of risk models. However, due to its voulme, UGC content needs to filtered by a risk model, and the problematic contents will enter a second round review process. Only after reviews the content can be recommended by the system.
If a content received a certain amount of comments/user interactions, been reported, or received negative feedback, it will go back into the review process and potentially been taken down if deemed problematic.

Risk models for content recognition can mainly be classified as pronographic content detection model, vulgar content detection model, and abusive content detection model.
- Pornography content detection model is trained on tens of millions of image data, used ResNet model, and has a recall of 99%
- Vulgar content detection model is trained on large database of both images and texts with over a million sample data, deep neural net model, with precision of 80%+ and recall of 90%+. This model is used against user replies/comments in addition to contents.
- Abusive content detection model is trained on large database of both images and texts with over a million sample data, deep neural net model, with precision of 80%+ and recall of 90%+. This model is used against user replies/comments in addition to contents.
This part of the model pays more attention to the recall rate, and the accuracy rate can even be sacrificed. The sample database of the abusive model also exceeds one million, with a recall rate of 95% + and an accuracy rate of 80% +. If users often speak out or make inappropriate comments, we have some penalties.

ByteDance also has Low quality content identification models for detecting low quality contents in wide variety of situations such as fake news, attack journalisms, mismatching of description and content, click baits, etc. These content are quite a challenge for neural machine understanding and requires a lot of reviewer feedbacks and labeling, including samples of different types.
Currently the precisions and recalls of the model is not good enough and require reviewers to audit the outputs to improve the threshold. With human in the loop, the recall is now around 95%. There’s still a lot of work that’s remained to be done. TouTiao’s AI Lab Prof Li Hang is jointly building a research project with the University of Michigan to set up a rumor recognition platform.
References:
1. 今日头条算法原理, 资深算法架构师曹欢欢博士 Tautiao Algorithms [Cao 2018]
2. Deep Neural Networks for YouTube Recommendations, [Covington 2016]