Data Aggregation Is Not a Moat
For years, a lot of data businesses were not really selling unique or proprietary data. They were selling the operational burden of collecting, cleaning, storing, analyzing, and packaging data into a useful downstream application.
That workflow looked roughly like this:
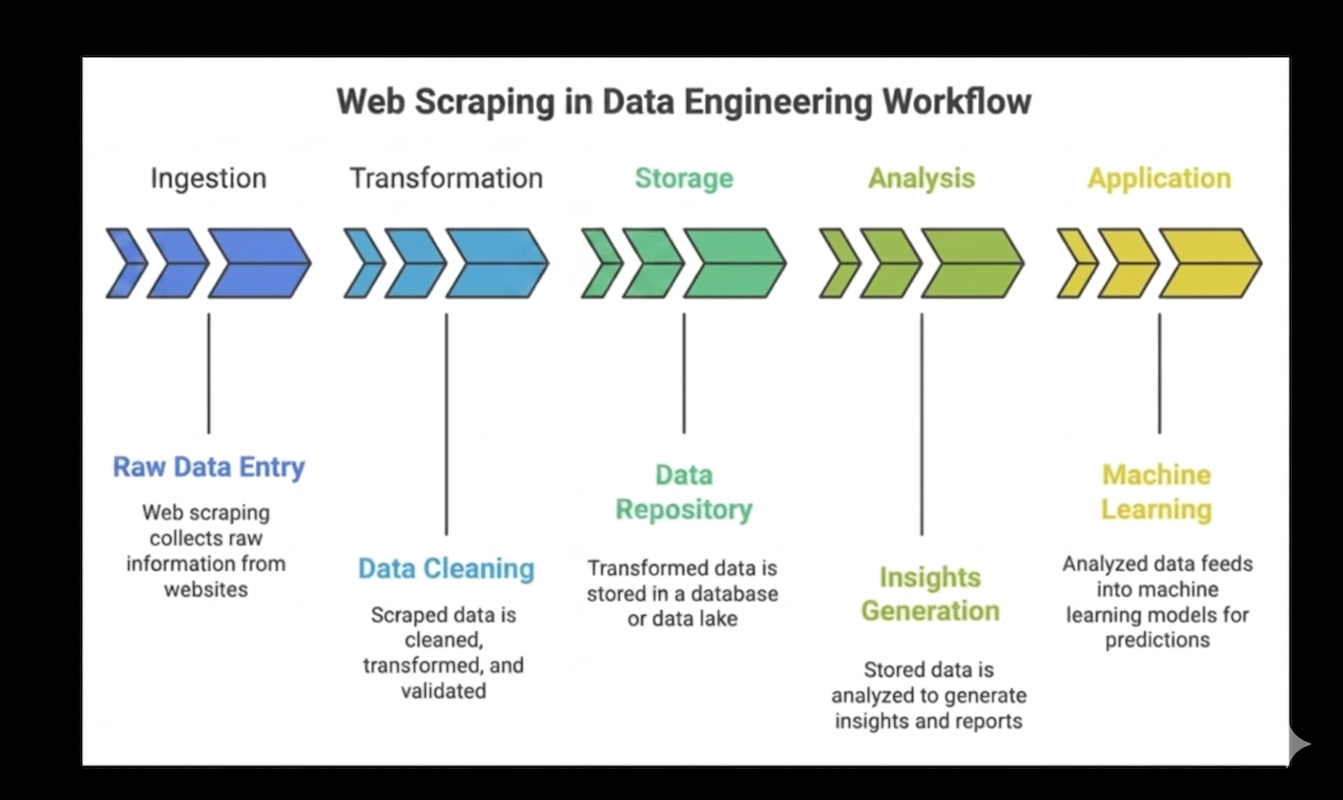
The moat was that every step in the pipeline was annoying and expensive to operate. You had to know which sources mattered. You had to get licenses. You had to get access. You had to deal with sessions, rate limits, anti-bot systems, and changing page structures. You had to parse messy HTML, clean noisy records, normalize schemas, store the data, refresh the pipeline, and then turn the output into something a customer could actually use.
AI agents compress this cost structure.
Instead of writing brittle crawler code against fixed page structures, a user can describe the workflow in plain language. The agent can choose sources, navigate through a browser, use permitted logged-in sessions, read pages semantically, clean noise, summarize the result, and package the output. The pipeline starts to move from a maintained software system to an on-demand user workflow.
This is the old Semantic Web and web-agent idea coming back through a different path.
In the 1990s, the hope was that the web would become machine-readable through standards, metadata, ontologies, and cooperative publishing. That mostly failed at web scale because the incentives were wrong. AI agents route around that failure. They do not need every website to expose perfect semantic markup. They can interpret messy human-facing interfaces directly.
AI breaks data moats.
A real proprietary data moat still matters. Unique first-party transactions, exclusive rights, private telemetry, regulated records, and high-quality feedback loops unavailable to others remain defensible.
But most “data moats” are not that. They are collections of public, semi-public, or non-exclusive data wrapped in operational competence. Their defensibility came from the cost of aggregation, not from ownership of the underlying facts.
When the aggregation cost collapses, the moat collapses with it.
If a motivated user can ask an agent to recreate a useful slice of the dataset on demand, the static database becomes less valuable. If the agent can perform the research workflow directly, the dashboard becomes less valuable. If the agent can refresh the result every morning as a scheduled task, the monitoring service becomes less valuable.
The value shifts upward.
The defensible layer is no longer “we collected the public and private data.” It is trust, provenance, permissioning, workflow integration, evaluation, compliance, and, most importantly, the AI/ML models and systems built on top of those data assets.
The important question is no longer: who has the biggest pile of aggregated data? It is: who can produce a decision-quality answer that is current, verified, auditable, and integrated into the user’s work?
Data aggregation is not going away. Search-scale crawling, archival indexing, compliance-grade records, and high-volume pipelines still need serious infrastructure.
But the long tail of crawler-backed products is about to get repriced.
OpenAI and Anthropic are the highest-value version of the same pipeline.
OpenAI publicly documents separate crawlers for different jobs: OAI-SearchBot for search, ChatGPT-User for user-directed browsing, and GPTBot for web content that may be used to train generative AI foundation models. OpenAI also says its foundation models are developed from a mix of public internet information, data accessed through partnerships, and data provided or generated by users, human trainers, and researchers.
Anthropic has the same pattern. It documents ClaudeBot as a crawler that collects public web content that could contribute to model training, alongside separate agents for user-directed retrieval and search. Anthropic’s privacy materials also describe training data sources that include publicly available internet information, commercially obtained datasets, and data provided by users or crowd workers, while stating that it does not bypass password-protected pages or CAPTCHA controls.
The important business point is not that these labs aggregate data. Everyone in the data stack has done some version of aggregation. The important point is where the economic value lands.
They do not stop at ingestion. They clean, filter, transform, evaluate, post-train, and compress the data into model weights. Then they expose the result through products, APIs, coding agents, search, enterprise workflows, and developer platforms.
That is the full value chain: public, licensed, and user-provided data goes in; intelligence-as-a-service comes out. The model captures far more of the economic value than the raw dataset ever could.
The old business sold a maintained pile of gathered data. The new workflow gives the user an agent that gathers, reasons, and acts when the need appears.
Dataset as product is being compressed into an on-demand workflow that turns raw information into action.