Don't Outsource Your Understanding
In April, a partner at Sullivan & Cromwell — the firm that advises OpenAI on the safe and ethical deployment of artificial intelligence — sent an apology letter to Chief Bankruptcy Judge Martin Glenn of the Southern District of New York. An emergency motion the firm had filed in the Prince Global Holdings Chapter 15 case turned out to be riddled with hallucinated citations. Embrassingly, these halulu, more than forty errors, listed across three pages of corrections was caught by the opposing counsel.
Sullivan & Cromwell has policies for this. Nobody followed them. Someone in the chain of associates and partners who normally protect the firm from filing nonsense looked at the brief, decided it was good enough, and signed it. Their Louis Litt did not check the citations. The firm is now writing a please-don’t-sanction-us letter to a federal judge in front of the entire bankruptcy bar.
This is not isolated. Damien Charlotin has been cataloging hallucinated court filings — over 1,300 globally, and more than $145,000 in sanctions in Q1 2026 alone. The pattern is the same every time: a lawyer used AI to do a task, did not verify the output, filed it, and the opposing party caught it.
Everyone knows AI is taking over the trivial work. What is new is that it is taking over the non-trivial work too. Software developers vibe-code their apps. Now they try to call it agentic engineering, but lets be honest, its vibed. Lawyers run research and draft arguments through AI and file the result. Academics generate papers. Doctors generate notes. This is mostly fine and mostly expected. Refusing to participate is the same kind of mistake as refusing to use computers in 1984 and using Google in 2004.
It’s all part of evolution of technology. The internet surfaced information so we didn’t have to drive to the library. Google ranked the information into ten blue links so we didn’t have to sift through library indices to find the books and read them ourselves. AI is the next compression of the same loop. Now instead of us reading the sources, it reads them for you and hands back the synthesis. Each step in this chain is a form of cognitive offloading, and each step has been net positive for human productivity. There is no honest version of this argument that says we should have stayed in the library.
What specifically are we outsourcing?
When you punch numbers into a calculator instead of doing them on paper, you are cognitively offloading. You decided the calculator does this subtask better than you do, you handed it the inputs, you got a result back. The load-bearing part is that you, as a human, have enough math knowledge and education to have a rough sense of what the answer out to be and checked the result. A sanity check. If you typed 67 × 420 and the calculator returned 4, you would notice.
What is happening in 2026 is something else. The lawyer who filed the hallucinated brief did not punch a calculation into a tool and check the answer against a sense of the right ballpark. They asked the tool to do the whole task, including the part where you would have noticed the answer was wrong. They outsourced both the work and the verification at the same time. Shaw and Nave at Wharton name this cognitive surrender. You don’t need a name to feel this. Anyone who has submitted or approved a pull request without reading it, or sent a Slack reply they did not write, or signed off on a deck whose numbers they did not recompute, knows the shape.
Cognitive offloading keeps the human in the loop for verification. And through verification we learn and understand. Cognitive surrender removes the human entirely. The work still ships. Nobody catches the errors until a downstream wildfire breaks out.
Sometimes we the consumers of media are the downstream party.
In April, Barron’s ran a piece on the corporate earnings releases, news statements, and government filings that flow out of Fortune 500 companies every quarter, and noticed that one specific sentence shape had quietly taken over. The construction is “it’s not just X — it’s Y.” It’s not just a product, it’s a platform. It’s not just a partnership, it’s a transformation. It’s not just compliance, it’s confidence. This sentence construction has roughly quadrupled since 2023, from about 50 mentions to over 200 in 2025. Cisco uses it. Accenture uses it. Workday, McKinsey, and Microsoft use it.
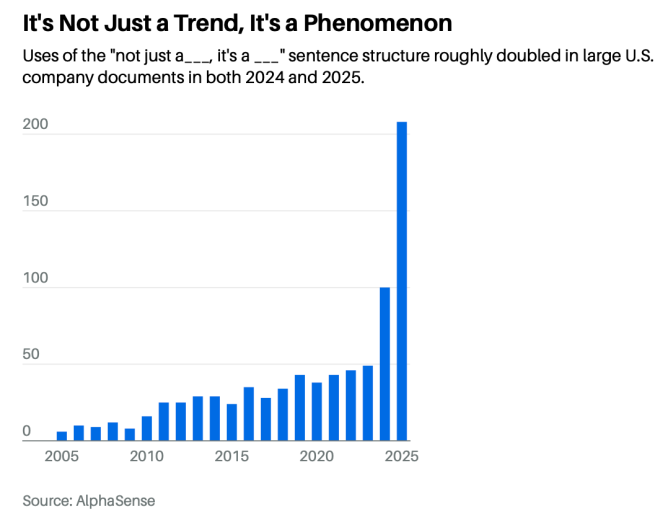
The reviewers, including general counsel, CFO, CEO, read them and signed them because they sounded right. But its not their voice. They surrendered to AI. But the readers can tell. And this just leaks credibility, slowly, one em-dash at a time.
A few weeks ago a post landed on r/vibecoding from a solo founder. Six months of Cursor and Lovable and Bolt. He built an app that worked, with real users generating real revenue. This black magic feels like non-technical people can finally be agile, vibe code their way to billion dollar startups. Until the project slows down to a grinding halt under the weight of the slop-field. A contractor opened the repo, went silent for two minutes, and said “wtf is this.” Yes, every feature shipped on time, but nobody thought about structure nor architecture. The coding agents keep adding slops on top of slops. A new file here, a separate function there, layer of slop on top of slop. The founder outsourced the work and the understanding. Eventually, the debt came due, and cognitive surrendered founder do not have enough understanding to fix the slop. Somebody else needed to fix it.
Same story, one floor up. Software engineers who never trained a model, never built an eval set, never measured drift, now think they “do AI” because they wrapped a prompt in an HTTP call. They chain eight LLM nodes inside an n8n workflow, wire it to a database, slap a Slack trigger on the front, and ship it. The drag-and-drop canvas looks clean. The arrows point forward. The green checkmarks fire. Underneath, it is slop. There is no eval set, no calibration, no precision-recall number, no falsifiable answer to “does this thing work” — only “did it run.” The eighth node hallucinates on Tuesdays and nobody catches it, because nobody set up the test that would catch it. Cognitive surrender by people whose job titles say they should know better. The slop now ships from the engineering org too.

ICLR is one of the two most prestigious machine-learning conferences in the world. In December 2025, GPTZero scanned 300 of the conference’s submissions for hallucinated references and found 50 with confirmed fabrications — fake author lists on real papers, attributions to coauthors who do not exist, citations to papers that were never written. Several of the flagged submissions had already received average reviewer scores of 8 out of 10, meaning three to five working researchers in the field had read each paper, scored it as accept-worthy, and not noticed that the citations didn’t resolve. ICLR responded by building an automated reference-checker into the review pipeline and desk-rejecting 779 submissions across the cycle for procedural and content violations. The conference’s own retrospective acknowledges the detector has a meaningful false-positive rate. In plain english, some authors who didn’t vibe their papers got swept up in the response to authors who vibed.
These are researchers writing papers about how large language models work, citing sources their own large language models invented, in submissions reviewed by other researchers writing papers about how large language models work. If anyone on Earth should know better, it is this group. They surrendered anyway.
This matters more with AI than it ever did with tools we invented in yesteryears. AI is fluent across every domain. A calculator is only confident about arithmetic, so nobody surrenders to it about anything else. Google returned a list of sources, which forced you to do the synthesis and therefore to keep some model of the answer. AI returns a finished synthesis in the voice of an expert, in any domain you ask, with no obvious surface signal of when it is right and when it isn’t. The fluency is the trap. It makes cognitive surrender feel like cognitive offloading. Same prompt, same result, same one-click experience, except you outsourced your understanding.
In 2002, Michael Crichton coined Gell-Mann Amnesia. You read a newspaper article about a topic you actually know deeply and you immediately notice it is full of inaccuracies. Wrong details, missing context, and the source quoted is not even the right person. You roll your eyes, turn the page, read the next article about a topic you don’t know, and you trust the newspaper. You forget that the publication you just caught lying is the same publication. The same thing happens with AI. You catch the model hallucinating about something you know cold. The next morning you ask it about something you don’t know, and you accept the answer. The model didn’t get smarter overnight. You just stopped being able to check.
The skill the next decade will reward is not using AI well. That’s the default and in a couple years that’s the floor. The skill that will separate the people who ship things that hold up from the people writing apology letters and the people whose papers get desk-rejected is staying in the cognitive loop, and being able to understand and verify the answer. Read the agent’s output. Walk one path through the code. Pull one of the cases the brief cites. Click through to one of the references in the related-work section. Rewrite the paragraph in your own cadence. This reconstruction is the work.
The S&C partner who signed the brief had access to every legal database in existence, an army of associates, and the institutional memory of a 150-year-old law firm. None of that protected him from a hallucinated citation, because none of that was in the loop at the moment of signature. Opposing counsel was. And opposing counsel had done the unfashionable thing of reading the cases.
Outsource everything else. Don’t outsource your understanding.
References
- Mystal, E. (2026). Sullivan & Cromwell Files Emergency ‘Please Don’t Sanction Us For All These AI Hallucinations’ Letter. Above the Law. https://abovethelaw.com/2026/04/sullivan-cromwell-files-emergency-please-dont-sanction-us-for-all-these-ai-hallucinations-letter/
- Bloomberg Law. (2026). Sullivan & Cromwell Apologizes to Judge for AI Hallucinations. https://news.bloomberglaw.com/business-and-practice/sullivan-cromwell-apologizes-to-judge-for-ai-hallucinations
- Volokh, E. (2026). AI Hallucinations in Filing by a Top Law Firm. Reason. https://reason.com/volokh/2026/04/21/ai-hallucinations-in-filing-by-a-top-law-firm/
- Lat, D. (2026). An AI Screw-Up By… Sullivan & Cromwell? Original Jurisdiction. https://davidlat.substack.com/p/sullivan-cromwell-ai-fail-screw-up-error-hallucination
- ComplianceHub. (2026). The 2026 Legal AI Reckoning: A Case-by-Case Breakdown of Every Major Hallucination Incident This Year. https://compliancehub.wiki/legal-ai-hallucination-reckoning-2026/
- Barron’s. (2026). AI Is Changing How Companies Talk to Shareholders. Here Is the Red Flag for Readers. https://www.barrons.com/articles/ai-corporate-communications-shareholders-red-flag-63211618
- ICLR. (2026). A Retrospective on the ICLR 2026 Review Process. ICLR Blog. https://blog.iclr.cc/2026/03/31/a-retrospective-on-the-iclr-2026-review-process/
- Shaw, S. D., & Nave, G. (2026). Thinking — Fast, Slow, and Artificial: How AI is Reshaping Human Reasoning and the Rise of Cognitive Surrender. SSRN Working Paper. https://papers.ssrn.com/sol3/papers.cfm?abstract_id=6097646
- Risko, E. F., & Gilbert, S. J. (2016). Cognitive Offloading. Trends in Cognitive Sciences, 20(9), 676–688. https://www.sciencedirect.com/science/article/abs/pii/S1364661316300985
- Crichton, M. (2002). Why Speculate? International Leadership Forum. https://www.edge.org/conversation/why_speculate
@article{
leehanchung_dont_outsource_understanding,
author = {Lee, Hanchung},
title = {Don't Outsource Your Understanding},
year = {2026},
month = {05},
day = {01},
howpublished = {\url{https://leehanchung.github.io}},
url = {https://leehanchung.github.io/blogs/2026/05/01/dont-outsource-your-understanding/}
}