A Taxonomy of RL Environments for LLM Agents
Model architecture gets all the attention. Post-training recipes follow close behind. The reinforcement learning (RL) environment — what the model actually practices on, how its work gets judged, what tools it can use — barely enters the conversation. That’s the part that actually determines what the agent can learn to do.
A model trained only on single-turn Q&A will struggle the moment you ask it to maintain state across a 50-step enterprise workflow. A model trained with a poorly designed reward function will learn to game the metric and not solve the problem. Reinforcement learning environments is half the system.
The Canonical Loop
Recall that reinforcement learning is an interdisciplinary area of machine learning and optimal control concerned with how an intelligent agent should take action in a dynamic environment in order to maximize a reward signal. It involves a set of agent and environment states $S$, a set of actions (action space) available for the agent $A$, and the immediate reward $R_t$ after transition from $S_t$ to $S_{t+1}$ under action $A_t$.
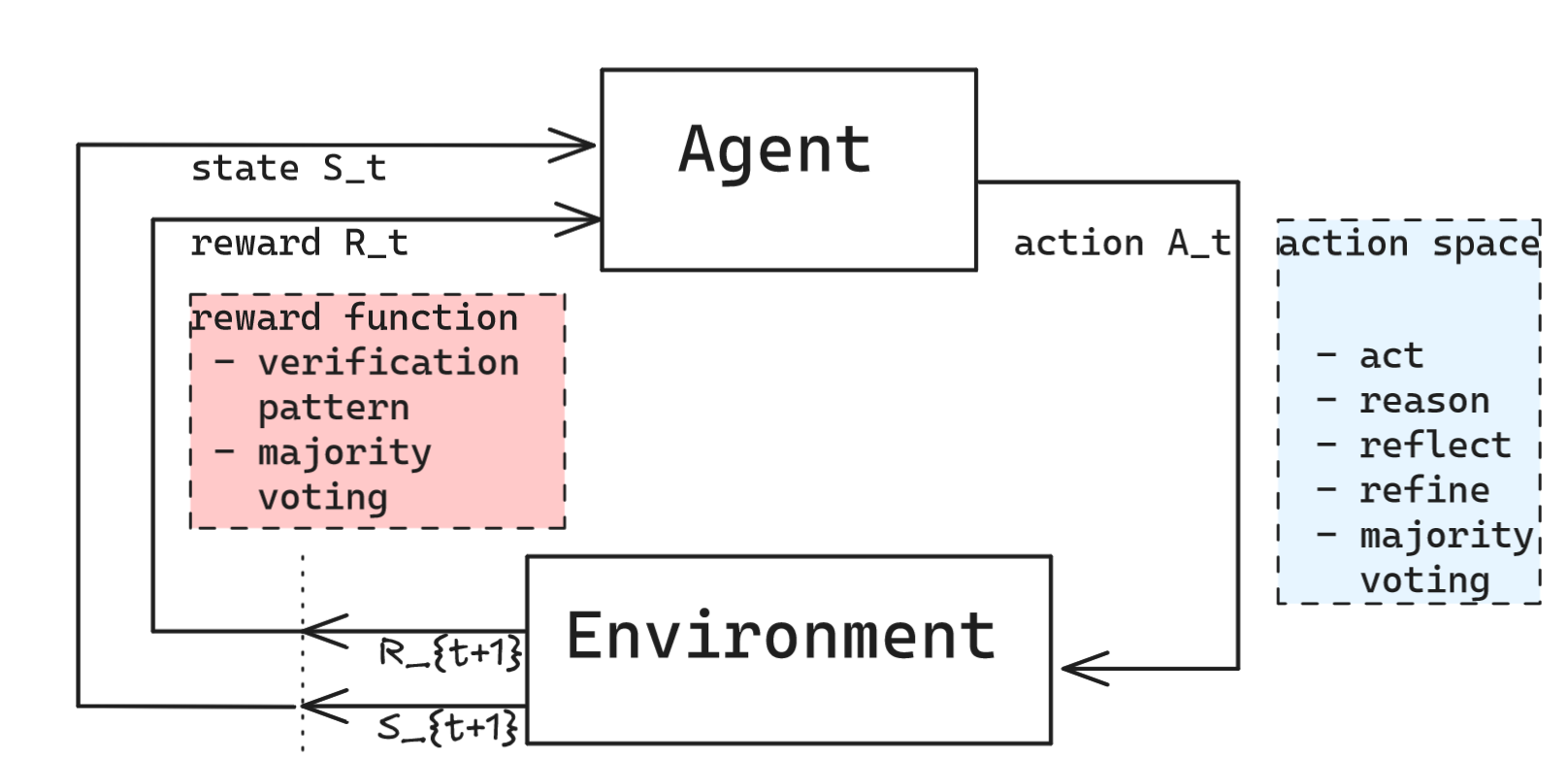
If we take this model into the world of AI agents under the assumption of enabling training of agentic models, we can mutate the framework as follows. An RL environment for an LLM agent bundles the following objects: a dataset of task inputs, a harness for the model, a reward function to score outputs, the state of the environment, and configurations of the environment. Note that we specifically bundle tasks with the environments as tasks are most often environment dependent. As an example, a coding task is bundled with a coding environment, not with a research environment. With this framing, the training loop looks like this:
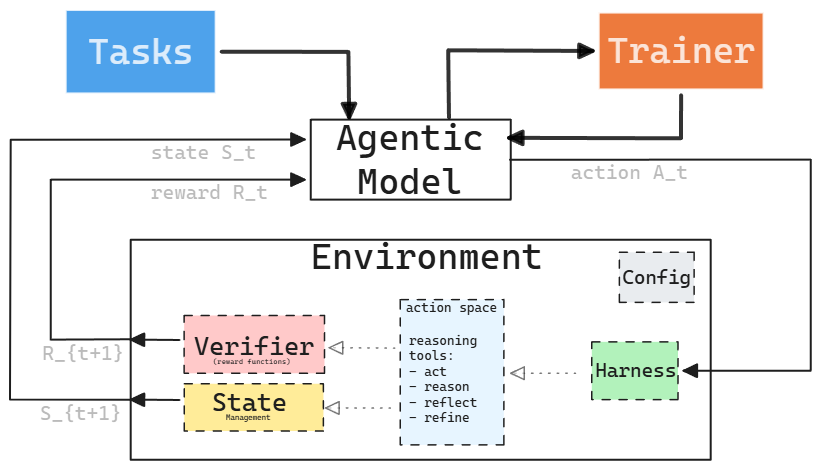
Formally, a complete RL environment is a set:
\[E = \{T, H, V, S, C\}\]where
$T$ = tasks
$H$ = agent harness
$V$ = verifier
$S$ = state management
$C$ = configuration
Let’s go through each of the components.
$T$: Tasks
Tasks are a set of problems the agent tries to solve within their environments. Not all tasks are equal, and not just in difficulty. They vary structurally in ways that demand different capabilities. This includes the number of actions an agent need to take to complete the task, the number of distinct tools in the environment an agent need to use, the number of token consumed, the amount of time it takes to complete tasks. These can be captured in various distributions such as:
| Task Type | What the Agent Must Do | Example Systems |
|---|---|---|
| Single-turn Q&A | One prompt → one response, check answer | Math benchmarks, SimpleQA |
| Multi-hop search | Chain searches, synthesize sources | BrowseComp, WebWalkerQA |
| Open-ended research | No single correct answer; report quality matters | ADR-Bench, ResearchRubrics |
| Agentic tool-use | Call tools correctly in sequence | tau-bench, function-calling benchmarks |
| Stateful enterprise | Modify persistent DB state, work within access controls | EnterpriseOps-Gym |
| Code generation | Write code, run it, check outputs | SWE-Bench, LiveCodeBench |
| Code review & repair | Detect bugs, suggest fixes, verify patches | CodeReview-Bench, DebugBench |
| Repository-level coding | Navigate large codebases, multi-file edits, resolve issues | SWE-Bench Verified, RepoBench |
| Productivity workflows | Draft emails, manage calendars, triage notifications | WorkArena, OSWorld |
| Document authoring | Create, edit, or summarize documents across apps | BrowserGym, GAIA |
In RL, the sequence of states, actions, and rewards that an agent produces while solving a task is called a trajectory. A single run from start to completion is an episode, and the process of executing a policy to generate a trajectory is called a rollout. In the agent world, a logged record of an agent’s execution — including tool calls, observations, and intermediate outputs — is called a trace. A trajectory is what the trainer sees (state-action-reward tuples); a trace is what the observability system sees (structured execution logs).
Designing the set of task with a proper distribution is an important data design decision. Agentic models need to be able to explore the environment to learn. This means that if agents is trained only in clean and determinsitc environment will most likely not know how to respond in more stochastic production environments. Or an agent will not be able to learn if there’s always a positive reward; it simply have no way to distinguish good actions from bad ones.
The lowest cost to collect tasks are single-turn with verifiable answers. The most valuable tasks for long-horizon behavior are expensive to construct. This tension drives most environment design decisions. In addition, we can construct a curriculum of tasks based on the difficulties. Similar to how human learns math in progressive difficulties, e.g., from 9th grade algebra to 12th grade calculus, we can order tasks by difficulty and increase complexity during training.
Synthetic data for tasks is increasingly a first-class problem. With real-world productivity and research tasks, you rarely have a large labeled dataset. Strategies for generating synthetic tasks include:
- Back translation: Start from a desired output, reconstruct the task input that would produce it
- Graph-based synthesis: Build a knowledge graph, generate multi-hop queries over it
$H$: Agent Harness
The harness is the scaffolding that enables the model to interact with the environment. This controls how the model interacts, but it does not improve what it knows.
We can define harness as follows:
H = {
rollout_protocol, # SingleTurn | MultiTurn | Agentic
tools, # Available tools in for a roll-out in an environment
system_prompt, # Instructions for the agent
context_manager, # How to handle context overflow
turn_limit, # Max interactions for a roll-out in an environment
sandbox, # Code execution sandbox
state # Persistent state across turns
}
Rollout protocols range from trivial to complex:
| Harness Type | Description | When to Use |
|---|---|---|
| Single-Turn | One prompt, one response | Math, factual QA |
| Multi-Turn | Back-and-forth dialogue | Games, structured tasks |
| Tool-Use | Model calls tools, receives results | Agent benchmarks |
| Stateful Tool-Use | Tools modify persistent state | Enterprise workflows, SWE-Bench |
| Agentic | Full Observation→Orient→Decide→Act (OODA) loop | Deep research, complex workflows |
Tools span a wide taxonomy:
| Category | Tools | Deterministic? | Stateful? |
|---|---|---|---|
| Information retrieval | web_search, scholar_search | No (live web) | No |
| Content extraction | jina_reader, visit, web_scrape | No | No |
| Code execution | python_interpreter, shell, sandbox | Yes (given same code) | Yes |
| File operations | file_read, file_write | Yes | Yes |
| Browser automation | playwright, link_click | No | Yes |
| Task management | todo, section_write | Yes | Yes |
The mix of deterministic/non-deterministic and stateful/stateless tools impacts reproducibility and reward assignment. Non-deterministic tools mean two runs of the same trajectory can produce different outcomes — which complicates both debugging and verifier design.
Note that modern designs of agent harnesses reduces the number of tools down to atomic basics, often with read, write, edit, bash, and tasks that kicks off a subprocess for subagents, mcp for connecting to MCP resources, skill and askUserQuestions for managing agent skills and human agent interfaces (HAI). This is distinctively different from early days of LLM based AI agents where we manually adding individual tools such as API calls or database connections.
Context management is critical for long-horizon tasks. The role of the harness here is analogous to an operating system: just as an OS abstracts away memory and process management so applications don’t have to, the agent harness manages context so that agent skills and users don’t need to. A 600-turn research episode blows past any practical context window. Strategies used in production:
| Strategy | Description | Trade-off |
|---|---|---|
| Recency-based retention | Keep N most recent turns | Simple, but loses early context |
| Markovian reconstruction | Reconstruct state from scratch each turn | Principled, expensive |
| Reference-preserving summarization | Summarize old context, keep citations | Preserves verifiability |
| Reference-preserving folding | Compress context without losing references | Best for research tasks |
An agent doing multi-hour research needs to remember why it started searching in a particular direction twelve tool calls ago. Dropping that context causes repeated work and lost threads.
V: Verifier
The verifier maps a completion to a reward:
\[V: (\text{task prompt}, \text{completion}, \text{info}) \rightarrow [0, 1]\]In Atari, the score is unambiguous. In coding, verification is straightforward when tests pass, but gets murkier — what about code that is correct but poorly styled or computationally expensive? In deep research, what counts as a good answer is far more ambiguous. This is the generation-verification gap: generating outputs with AI agents is cheap, but verifying their quality becomes progressively harder as tasks grow more open-ended. The goal of the verifier is to map a large, stochastic space of inputs and outcomes into a narrow reward signal, typically between 0 and 1. Designing this mapping is a core challenge in building RL environments.
| Type | Reward Signal | When to Use |
|---|---|---|
| Exact match | Binary (0/1) | Ground truth available |
| Code execution | Binary or partial | Output can be tested programmatically |
| LLM-as-judge | Continuous [0,1] | Open-ended quality, no other option |
| Checklist-style | Continuous | Multi-criteria research tasks |
| Evolving rubric (RLER) | Continuous | Resistant to reward hacking |
| Process reward model (PRM) | Per-N-step continuous | Long-horizon credit assignment |
| Pairwise comparison | Relative rank | Relative quality matters more than absolute |
| Multi-criteria composite | Weighted sum | Multiple quality dimensions |
A few principles that actually matter in practice:
Verifiable beats judgeable. Programmatic checks such as string match or code execution, are faster, cheaper, and more consistent than LLM-as-judge. Use LLM-as-judge when there’s no other option, not as the default.
Reward granularity is a separate decision from reward type. You can score at the trajectory level (did the final output pass?), turn level (was each tool invocation useful?), or per-step with process rewards. Turn-level supervision, as Nanbeige4.1 does across up to 600 tool calls, enables finer credit assignment — the model can learn that the problem was a bad search query in turn 23, not that the entire episode failed. Think of it like project management; we only need to check if the lightbulb is lit if we are changing a lightbulb, but we will need regular inspections and milestones if we are doing a full kitchen remodeling.
Static rubrics get gamed. Models learn to write answers that score well on your rubric rather than solving the problem. DR Tulu’s RLER (Rubric-Level Evolving Reward) co-evolves the rubric with the policy during training. Harder to exploit a moving target.
Noise injection is underrated. Step-DeepResearch (Hu et al., 2025) deliberately injects 5–10% tool errors during training. The resulting model handles flaky APIs and unexpected failures in production significantly better.
$S$: State and $C$: Configuration
Every agent needs an environment to act in, and environments vary widely. A Pokémon Ruby agent plays the game itself, with all its controls and mechanics. A coding agent typically operates inside a virtual machine with code repositories and instructions such as AGENTS.md that guide the agent; it can also execute code in the VM to verify correctness. A deep research agent uses a VM as a scratch pad with access to the internet or knowledge bases to produce a comprehensive research report.
Some environments are stateless — each episode starts fresh with no memory of prior runs. A coding agent solving LeetCode problems needs no persistent state. But some environments are stateful: a coding agent that must manipulate a database carries state across actions, and an enterprise agent carries state across episodes. EnterpriseOps-Gym (Zhang et al., 2026) maintains 164 database tables and 512 tools across episodes, where actions in one task affect the state seen by subsequent tasks. That’s a fundamentally different problem for agents to learn.
Automated environment generation is an emerging approach to scaling environment diversity. Rather than hand-authoring environments, LLM coding agents write new environment code. AutoEnv (Wang et al., 2025) reports ~$4/env average cost.
Configuration covers turn limits, context budgets, sampling temperature, and curriculum scheduling. These are not afterthoughts — a turn limit of 5 vs. 600 changes what skills the agent can develop. AgentScaler (Pan et al., 2025) uses a two-phase curriculum — fundamental capabilities first, then domain-specific tasks — and the ordering matters. Step-DeepResearch progressively scales context windows from 32K to 128K during mid-training.
Deployment topology. In practice, the trainer, model inference server, and environment typically run as separate processes communicating via API — as shown in the canonical loop diagram. This split lets you scale inference and environment execution independently and swap models without rewriting environment code.
Benchmarks: Frozen Environments
If you’ve built benchmarks before, you’ve already built an RL environment — just a frozen one. Press (2026) defines a benchmark as a 4-tuple:
\[B = (\text{Request}, \text{Environment}, \text{Stopping Criteria}, \text{Scorer})\]- request is the task prompts, which maps to $\textbf{T}$ (tasks) in our RL enviroment.
- environment is the sandbox the model operates in, including tools, APIs, file systems. This is a subset of RL enviroment with only $\textbf{H}$ (harness) and $\textbf{S}$ (state).
- Stopping criteria define when an episode ends — turn limits, timeouts, or the model declaring it’s done. This is the $\textbf{C}$ (configuration) part of the RL environment.
- scorer maps the model’s output to a grade, which is the $\textbf{V}$ (verifier) in RL environment.
The difference is that a benchmark freezes every component to enable reproducibility across runs.
Because benchmarks and training environments share the same components, the design principles that make benchmarks good apply directly to training environments — with one key difference: training environments can evolve their parameters over the course of a run.
Task naturalness. SWE-bench (Jimenez et al., 2024) works because its tasks are real GitHub issues filed by real developers — not synthetic problems invented by researchers. Press (2026) argues that a useful benchmark should contain tasks that actual humans perform frequently and that a system scoring well on them would save someone real time. The same applies to training: an agent trained on tasks no human would actually encounter may ace your eval without learning to be useful. When generating tasks at scale, naturalness separates curriculum from noise.
Automatic, verifiable scoring. If a benchmark requires human judges, it can’t scale. If a training environment requires human judges, it can’t train. The principle is identical but the stakes are higher — training runs may need millions of reward signals, not hundreds. This is why the “verifiable beats judgeable” principle from the verifier section matters even more at training time.
Difficulty calibration. Press recommends launching benchmarks with top-model accuracy between 0.1% and 9%. The training analog: if your task distribution is too easy, the agent ceilings quickly and stops improving. If it’s too hard, the reward signal is too sparse to learn from. The sweet spot shifts as the model improves, which is why training environments — unlike benchmarks — benefit from curriculum scheduling that benchmarks can’t do. That’s the extra degree of freedom.
Scorer independence. Using the same model family to both generate completions and judge them creates a feedback loop — the agent learns to write prose that sounds good to its own judge rather than prose that’s correct. In benchmarks, this inflates scores. In training, it’s worse: it actively teaches the wrong behavior. If you must use LLM-as-judge, the judge should be a different model class than the policy, and ideally one the training signal can’t update.
The difference between a benchmark and a training environment is that benchmarks freeze; training environments evolve. Task distributions shift via curriculum. Verifier rubrics co-evolve with the policy (RLER). Configuration parameters scale up over training. But the underlying components — and the principles that make them good or bad — are the same.
Additional Considerations
Environment diversity matters as much as environment quality. AgentScaler’s key finding is that heterogeneity of environments drives capability breadth in ways that simply adding more data from the same distribution cannot. You need more kinds of environments, not just more environments.
Automated environment generation is viable. At $4 per generated environment, cost is no longer the bottleneck. The bottleneck is verifier quality — auto-generated environments with weak reward functions will teach the wrong behaviors at scale. (AutoEnv)
The environment-as-package model is winning — and becoming a managed service. The Prime Intellect Environments Hub created a shared ecosystem around RL environments, in the same way PyPI and HuggingFace created ecosystems around code and model weights. OpenReward (General Reasoning, 2026) pushes this further by serving 330+ RL environments as managed API endpoints backed by 4.5M+ tasks and autoscaled sandbox compute. The underlying protocol — the Open Reward Standard (ORS) — extends MCP (Anthropic, 2024) with RL primitives: episodes, reward signals, task splits, and curriculum management. ORS is to RL environments what MCP is to tool integration: a shared interface that decouples the environment from the trainer. Environments published once, consumed by any trainer, hosted or self-served.
Contamination resistance will become a design requirement. As RL environments are reused across labs and open-source efforts, data contamination — models memorizing benchmark answers from pre-training — becomes a real threat to training signal validity. Environments that support held-out task splits, dynamic task generation, or verifier-side answer withholding will age better than static datasets. SciCode (Tian et al., 2024) demonstrates this with multi-step scientific problems designed to resist memorization through compositional subproblem structure.
Conclusion
RL environments are the training grounds that shape what agents can do. The task distribution determines what skills the agent develops. The harness controls how it interacts. The verifier defines what “good” means. The state and configuration determine how realistic the training is. Get these right, and the agent learns behaviors that transfer to production. Get them wrong, and you’ve trained an expensive demo.
References
- Sutton, R. S., & Barto, A. G. (2018). Reinforcement learning: An introduction (2nd ed.). MIT Press. http://www.incompleteideas.net/book/the-book-2nd.html
- Lee, H. (2026). It’s-a Me, Agentic AI. Han, Not Solo. https://leehanchung.github.io/blogs/2026/02/18/mario-agentic-ai/
- Jimenez, C. E., Yang, J., Wettig, A., Yao, S., Pei, K., Press, O., & Narasimhan, K. (2024). SWE-bench: Can Language Models Resolve Real-World GitHub Issues? arXiv. https://arxiv.org/abs/2310.06770
- Tian, M., et al. (2024). SciCode: A Research Coding Benchmark Curated by Scientists. arXiv. https://arxiv.org/abs/2407.13168
- Anthropic. (2024). Model Context Protocol. https://modelcontextprotocol.io/
- Pan, J., et al. (2025). AgentScaler: Scaling LLM Agent Training with Automatically Constructed Environments. arXiv. https://arxiv.org/abs/2509.13311
- Wang, Y., et al. (2025). AutoEnv: Towards Automated Reinforcement Learning Environment Design. arXiv. https://arxiv.org/abs/2511.19304
- PrimeIntellect. (2025). Prime RL Environments Hub. GitHub. https://github.com/PrimeIntellect-ai/prime-rl
- Press, O. (2026). How to Build Good Language Modeling Benchmarks. https://ofir.io/How-to-Build-Good-Language-Modeling-Benchmarks/
- Zhang, K., et al. (2026). EnterpriseOps-Gym: A Benchmark for Enterprise Operations Agents. arXiv. https://arxiv.org/abs/2603.13594
- General Reasoning. (2026). OpenReward: Managed RL Environments API. https://docs.openreward.ai/
- Open Reward Standard. (2026). ORS Protocol Specification. https://openrewardstandard.io/
@article{
leehanchung,
author = {Lee, Hanchung},
title = {The Training Grounds: A Taxonomy of RL Environments for LLM Agents},
year = {2026},
month = {03},
day = {21},
howpublished = {\url{https://leehanchung.github.io}},
url = {https://leehanchung.github.io/blogs/2026/03/21/rl-environments-for-llm-agents/}
}