It's-a Me, Agentic AI
Agentic AI is a fairly recent development that combines reasoning (OpenAI, 2024) and tool use (Schick et al, 2023) in the same AI model. But an agentic AI system is not just the model, but also the harness, environments, tools, rewards, evaluations and benchmarks, and all of the infrastructure to support it. In this post, let’s use Super Mario, the classic Nintendo video game, to tell this story for understanding how agentic AI models are developed, how agent harnesses work, and how reinforcement learning ties everything together. If you survived World 8-4 as a kid, you already have the intuition for building agentic AI systems.
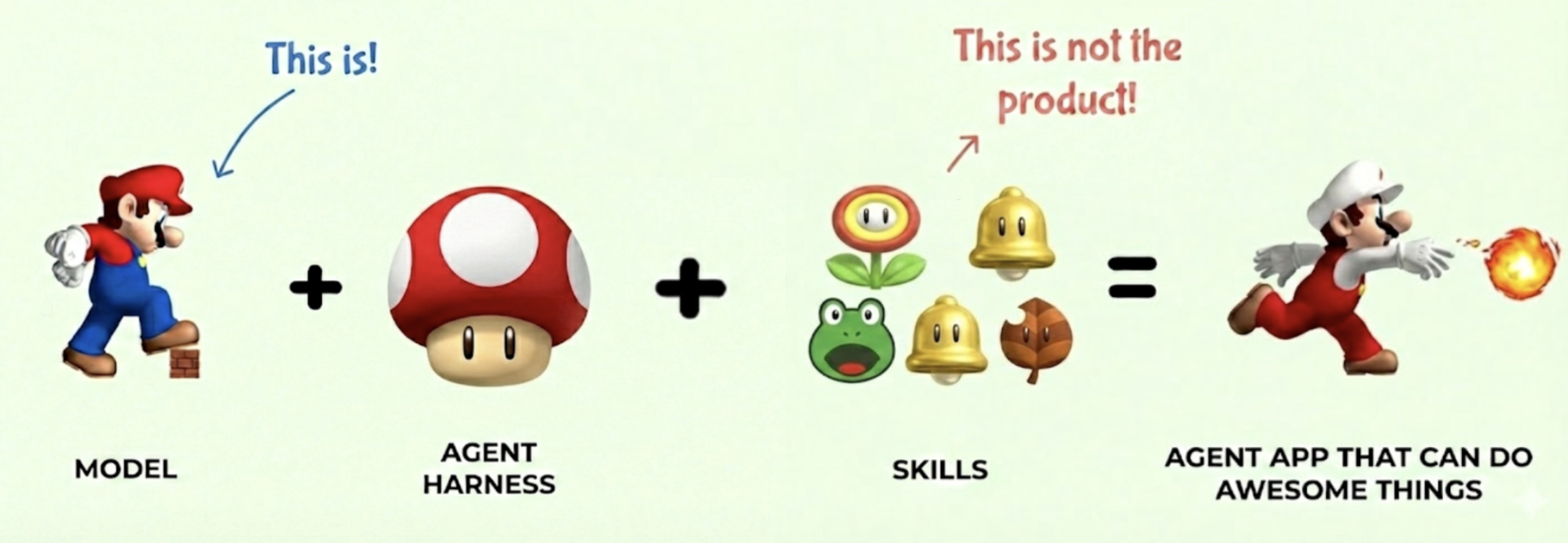
Small Mario: The Base Model

Small Mario is the base pretrained model. He’s just come out of pretraining on a massive corpus of platform game physics. He can walk, jump, and move left and right. These are his base capabilities, the raw knowledge compressed from the training data.
But Small Mario is fragile. One hit from a Goomba and he’s dead. He can’t break bricks or take damage. He has potential, but he’s not yet useful for anything beyond the most trivial tasks.
This is your base LLM fresh off pretraining. It has absorbed enormous amounts of knowledge, it can do next-token prediction, and it can sort-of follow instructions. But ask it to do anything real, reliably, in production, and it falls apart on the first obstacle. One Goomba and it’s game over.
The Super Mushroom is Agent Harness

Then Mario finds the Super Mushroom. He doubles in size. He can now break bricks. He can take a hit without dying. He goes from fragile to capable.
The Super Mushroom is the model harness. Once eaten, it transforms a base model into something production-ready. This includes:
- System prompts that define personality and constraints
- Safety guardrails so it can take some damage without dying
- Memory and context management so it remembers where it’s been
- Tool-use training so it knows power-ups exist and how to grab them
Without the Super Mushroom, Mario is a liability. With it, he now has potential for greatness. Similarly, without the model harness, a base LLM is a research artifact. With it, it’s has the potential to become a product.
The Super Mushroom doesn’t change WHO Mario is. It changes what he can SURVIVE. The model harness doesn’t change the model’s core knowledge. It changes what the model can handle in production.
Power-Ups are Agent Skills

Now here’s where it gets interesting. Super Mario can pick up power-ups that give him entirely new capabilities. These are agent skills:
| Power-Up | Mario Ability | Agent Equivalent |
|---|---|---|
| Fire Flower | Throw fireballs at enemies | Code execution — solve problems the model can’t solve with text alone |
| Frog Suit | Swim through water levels | Web search — navigate environments the model wasn’t trained on |
| Star | Temporary invincibility | Extended thinking — brute force through complex problems at higher compute cost |
| Cape Feather | Sustained flight | MCP servers — extensible access to external services and APIs |
Each power-up doesn’t replace Mario’s core abilities. Mario still walks and jumps. The power-ups extend what he can do. A Fire Flower Mario can still jump on Goombas, but now he can also shoot fireballs at Piranha Plants hiding in pipes.
This is exactly how agent skills and tools work. The LLM still does what LLMs do: reasoning, language understanding, and planning. Tools extend the model’s reach into environments it can’t operate in alone. An LLM can’t execute Python by itself, just like Mario can’t throw fireballs without a Fire Flower. But give it the right tool, and suddenly the problem space opens up.
And critically, Mario has to learn WHEN to use each power-up. Frog Suit is amazing in water levels, useless on land. Fire Flower is great against Goombas, pointless against Thwomps. The model needs to learn tool selection, knowing which tool to reach for in which context. This is one of the hardest parts of building agentic systems.

One power-up deserves special attention: the Star. When Mario grabs a Star, he becomes invincible. He plows through Goombas, Koopa Troopas, Piranha Plants, everything in his path just disintegrates. Nothing can stop him.
This is like having an engineering manager who’s really good at clearing organizational blockers for their engineers. The Goombas and Piranha Plants of bureaucracy, cross-team dependencies, access requests, and priority conflicts just melt away. Star power is temporary and expensive, but when you need to blast through a critical path, nothing else comes close.
The Mushroom Kingdom are environments

Now let’s talk about the world Mario operates in. Every level in the Mushroom Kingdom is an environment, and every environment is composed of the same building blocks. Some of these building blocks are tools that Mario can use:
| Level Element | Environment Equivalent |
|---|---|
| ? Blocks | Unknown information sources — sometimes containing exactly what you need |
| Pipes | Entry points to sub-tasks, function calls, or deeper exploration |
| Goombas | Common obstacles, predictable errors, edge cases |
| Pits | Catastrophic failures, unrecoverable errors |
Every level remixes these elements differently. World 1-1 is simple, a few Goombas, some bricks, a clear path to the flag. World 8-4 is a maze of pipes, hidden paths, and a boss fight with Bowser. Same building blocks, radically different difficulty.
Throughout each level, Mario interacts with the environment and the tools contained within. He enters pipes to warp from one place to another, the equivalent of an API call that transports you to an entirely different context. He bumps ? Blocks from below to discover power-ups, new agent skills materializing from the environment when you know where to look. He breaks bricks to clear paths or reveal hidden rewards, structured data yielding its value when you apply force in the right direction. He stomps on a Koopa shell and kicks it forward, turning an obstacle into a projectile that clears a line of Goombas, repurposing error outputs as inputs to solve downstream problems. The environment more than just a backdrop. It’s also a toolbox.

But the Mushroom Kingdom isn’t one level. It’s organized into Worlds, each with a distinct theme and set of challenges. World 1 is grassland with basic enemies. World 3 is water. World 6 is ice. World 8 is Bowser’s Castle. Each world is a collection of levels that share a common environment type and difficulty profile.
This maps directly to how we build agentic AI systems for the real world. A single environment — say, a coding sandbox — is one world. But to build an agent that operates across a full domain, you need a collection of world on a World Map: a collection of environments that together cover the breadth of that domain. A coding world includes environments for code generation, code review, rood cause analysis, and operations. An office productivity world includes email, calendar, document editor, and spreadsheets. A research world includes literature search, data analysis, and report writing.
| World | Theme | Agent Domain |
|---|---|---|
| World 1 | Grassland | Simple text tasks, Q&A, summarization |
| World 3 | Water | Web browsing and API navigation |
| World 6 | Ice | Debugging in fragile or legacy environments |
| World 8 | Bowser’s Castle | Full autonomous task completion under adversarial conditions |
Tasks and rewards
Having an environment is not enough. We need to define what we want to achieve from playing the game, and how we measure whether we achieved it. In RL terms, these are the tasks and the reward function.
Mario can play the same level with completely different objectives: complete the level, complete it as fast as possible, get the highest score, collect the most coins, accumulate the most 1-up lives, find all the hidden rewards, stomp on every last Goomba. Each objective produces a fundamentally different play style from the same environment. This is exactly the task definition problem in agentic AI. “Summarize this codebase” and “refactor this codebase” use the same files, the same tools, the same context, but they require entirely different strategies. The task is what transforms an environment from a sandbox into a mission.
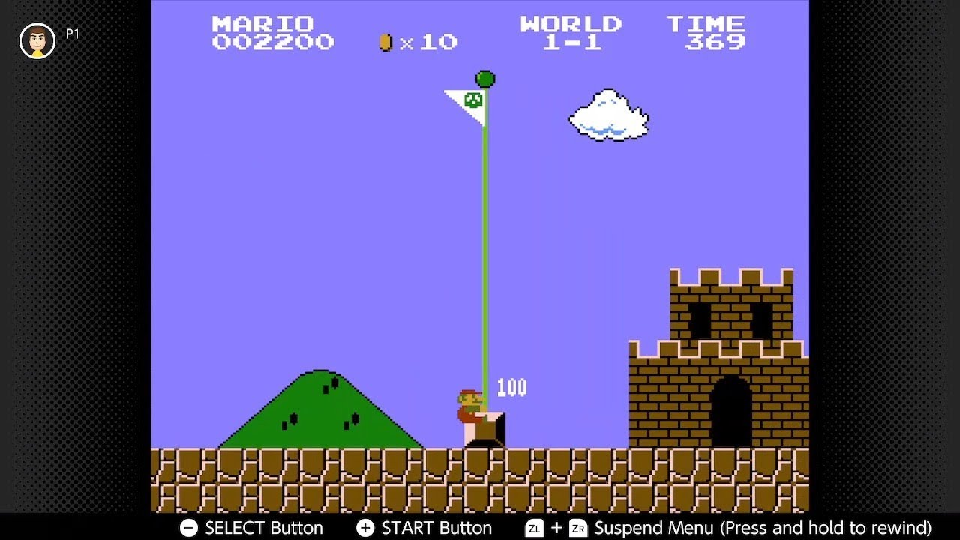
At the end of every level, there’s a flagpole. Mario jumps on it, pulls down the flag, and receives a reward. The higher he grabs the flag, the bigger the reward. Some levels end with a boss fight against Bowser, where the reward is freeing a Toad (or eventually, Princess Peach). This is the reward signal — the feedback that tells the agent how well it performed the task.
But how do we actually measure how well the game was played? This is reward modeling, and it is where the machine learning engineering discipline really shines. The evaluation could be the raw score, the number of 1-ups gained, coins collected, Goombas stomped, time remaining, or different paths discovered. Most frequently, it is a combination of some or all of the above, weighted and balanced against each other. Do we reward Mario more for speed or for thoroughness? For survival or for aggression? For finding secrets or for staying on the critical path?
| Evaluation Metric | Mario Measure | Agent Measure |
|---|---|---|
| Speed | Time remaining on the clock | Task completion latency |
| Score | Points accumulated | Overall output quality |
| Collection | Coins gathered | Information retrieved, resources used efficiently |
| Completeness | Hidden blocks found, secrets discovered | Edge cases handled, comprehensive coverage |
| Efficiency | Enemies defeated per life | Correct tool invocations per task |
| Exploration | Different paths taken | Novel approaches discovered |
Designing these rewards is a rigorous machine learning engineering discipline. A poorly shaped reward function produces an agent that technically completes tasks but in degenerate ways, like a Mario speedrunner who clips through walls. Impressive, but not what we actually wanted. Reward hacking is the Goodhart’s Law of agentic AI: when a measure becomes a target, it ceases to be a good measure.
Reinforcement Learning to learn play
Here’s where the full picture comes together. Reinforcement learning is Mario learn to complete the levels.
Mario starts each level knowing nothing about its specific layout. He has to:
- Observe the current state, what’s on screen, where the enemies are, what power-ups are available
- Decide on an action based on his policy, jump, run, shoot, or wait
- Act and receive feedback from the environment
- Update his policy based on the outcome
This is the MDP (Markov Decision Process) loop. The same loop described in Agents Are Workflows. The same loop that every agentic AI system runs:
\[v^\pi(s) = \mathop{\mathbb{E}}[r(s, a) + \gamma v_\pi(s^\prime)]\]The value of Mario’s current state equals the expected immediate reward plus the discounted value of the next state. Should Mario jump NOW to get the coin, or wait and avoid the Goomba? The optimal policy $\pi^*$ balances immediate rewards against future outcomes.
Through repeated play (training episodes), Mario learns:
- Which obstacles can be jumped on vs. avoided
- When to use power-ups vs. save them
- Which pipes lead to shortcuts vs. dead ends
- How to handle boss fights
An agentic AI model goes through the same process. Through reinforcement learning (PPO, DPO, GRPO, or whatever the latest acronym is), the model learns:
- Which tools to invoke for which subtasks
- When to think longer vs. act immediately
- Which approaches work for which problem types
- How to decompose complex tasks into manageable steps
And remember: Reinforcement learning does not make the agent harness smarter, nor the power ups. It improves the model and the model only. Thus, the model is the product.
The Engineers behind the controller
So who’s actually making all of this work? Mario doesn’t train himself.
To teach agent Mario to be really good at the game, we employ a Machine Learning Engineer (MLE) — also called a research engineer or applied AI engineer at some organizations. The MLE is the game designer and coach rolled into one. They build the environments that Mario will train in: deciding which levels to include, what obstacles to place, what tools to make available, and how to sequence difficulty so Mario faces progressively harder challenges. They set up the harnesses and tools, define the tasks that Mario needs to achieve, and most importantly, design the reward function. The MLE decides what “good” looks like. Do we reward Mario for speed? Thoroughness? Both? How much? Environment design and reward design are the two highest leverage decisions in the entire pipeline. Get them right and Mario learns to play beautifully. Get them wrong and Mario learns to exploit glitches, or never encounters the challenges he needs to grow.
This isn’t hypothetical. Here’s a real job posting from Anthropic’s Universes team, whose entire job is building training environments for AI models:

“Environments where models learn to navigate ambiguity, handle interruptions, maintain context over extended interactions, and exercise judgment in open-ended scenarios.” That’s World 8 — and somebody has to build it.
Once the MLE has designed the training setup, the Machine Learning Systems Engineers (MLSys) take over. They are the ones who actually run the show at scale. They set up the environment and agent Mario across hundreds to hundreds of thousands of environments, tasks and iterations. They manage the compute, the distributed training runs, the data pipelines. They collect the reasoning traces, the sequences of observations, actions, and outcomes from every single episode Mario plays. And from these traces, they run the reinforcement learning algorithms that allow agent Mario to learn from experience.
This is the unsexy but critical part. An MLE can design the most elegant reward function in the world, but without MLSys engineers standing up the infrastructure to run millions of training episodes and collect the resulting data, Mario never gets past World 1-1.
Conclusion
Small Mario needs a mushroom to survive, power-ups to be effective, levels to practice on, and a reward at the flagpole to learn from. That’s the whole agentic AI stack: base model, harness, tools, environments, tasks, rewards, and reinforcement learning.
Now go save Princess Peach.
References
- Sutton, R. S., & Barto, A. G. (2018). Reinforcement learning: An introduction (2nd ed.). MIT Press. http://www.incompleteideas.net/book/the-book-2nd.html
- Schick, T., Dwivedi-Yu, J., Dessì, R., Raileanu, R., Lomeli, M., Hambro, E., Zettlemoyer, L., Cancedda, N., & Scialom, T. (2023). Toolformer: Language Models Can Teach Themselves to Use Tools. arXiv preprint arXiv:2302.04761. https://arxiv.org/abs/2302.04761
- OpenAI. (2024). OpenAI o1 System Card. https://cdn.openai.com/o1-system-card-20241205.pdf
- Lee, H. (2025). Agents Are Workflows. Han, Not Solo. https://leehanchung.github.io/blogs/2025/05/09/agent-is-workflow/
- Lee, H. (2025). No Code, Low Code, Real Code. Han, Not Solo. https://leehanchung.github.io/blogs/2025/06/26/no-code-low-code-full-code/
@article{
leehanchung,
author = {Lee, Hanchung},
title = {It's-a Me, Agentic AI},
year = {2026},
month = {02},
day = {18},
howpublished = {\url{https://leehanchung.github.io}},
url = {https://leehanchung.github.io/blogs/2026/02/18/mario-agentic-ai/}
}