The Differences between Deep Research, Deep Research, and Deep Research
A wave of “Deep Research” releases has swept through frontier AI labs recently. Google unveiled its Gemini 1.5 Deep Research in December 2024, OpenAI followed with its Deep Research in February 2025, and Perplexity introduced its own Deep Research shortly after. Meanwhile, DeepSeek, Alibaba’s Qwen, and Elon Musk’s xAI rolled out Search and Deep Search features for their chatbot assistants. Alongside these, dozens of copycat open-source implementations of Deep Research have popped up on GitHub. It seems Deep Research is the Retrieval-Augmented Generation (RAG) of 2025—everything is being rebranded and marketed as “Deep Research” without a clear definition of what it actually entails.
Does this sound familiar? It echoes the hype around RAG in 2023, agents, and agentic RAG in months past. To cut through the clutter, this blog post examines the various flavors of “Deep Research” from a technical implementation perspective.
Deep Research, Deep Search, or Just Search
"”Deep Research uses AI to explore complex topics on your behalf and provide you with findings in a comprehensive, easy-to-read report, and is a first look at how Gemini is getting even better at tackling complex tasks to save you time. “- Google”
"”Deep research is OpenAI’s next agent that can do work for you independently—you give it a prompt, and ChatGPT will find, analyze, and synthesize hundreds of online sources to create a comprehensive report at the level of a research analyst.” - OpenAI
"”When you ask a Deep Research question, Perplexity performs dozens of searches, reads hundreds of sources, and reasons through the material to autonomously deliver a comprehensive report.” - Perplexity”
Stripping away the marketing jargon, here’s the concise definition of Deep Research:
“Deep research is a report generation system that takes a user query, uses large language models (LLMs) as agents to iteratively search and analyze information, and produce a detailed report as the output.”
In natural language processing (NLP) terms, this is known as report generation.
Implementations
Report generation - or deep research - has been a focus of the AI engineering since ChatGPT’s debut. I’ve personally experimented with it during hackathons in early 2023, a time when AI engineering was just taking off. Tools like LangChain, AutoGPT, GPT-Researcher, and prompt engineering, along with countless demos on Twitter and LinkedIn, have drawn significant attention. However, the real challenge lies in the implementation details. Below, we’ll explore common patterns for building report generation systems, highlight their differences, and classify offerings from various vendors.
Untrained: Directed Acyclic Graph (DAG)
Early on, AI engineers discovered that asking an LLM like GPT-3.5 to generate a report from scratch wasn’t practical. Instead, they turned to Composite Patterns to chain together multiple LLM calls.
The process typically works like this:
- Decompose the user query - sometimes using step back prompting (Zheng et al, 2023) - to create a report outline.
- For each section, retrieve relevant information from search engines or knowledge bases and summarize it.
- Finally, use LLM to stitch the sections into a cohesive report.
A prime example is GPT-Researcher.
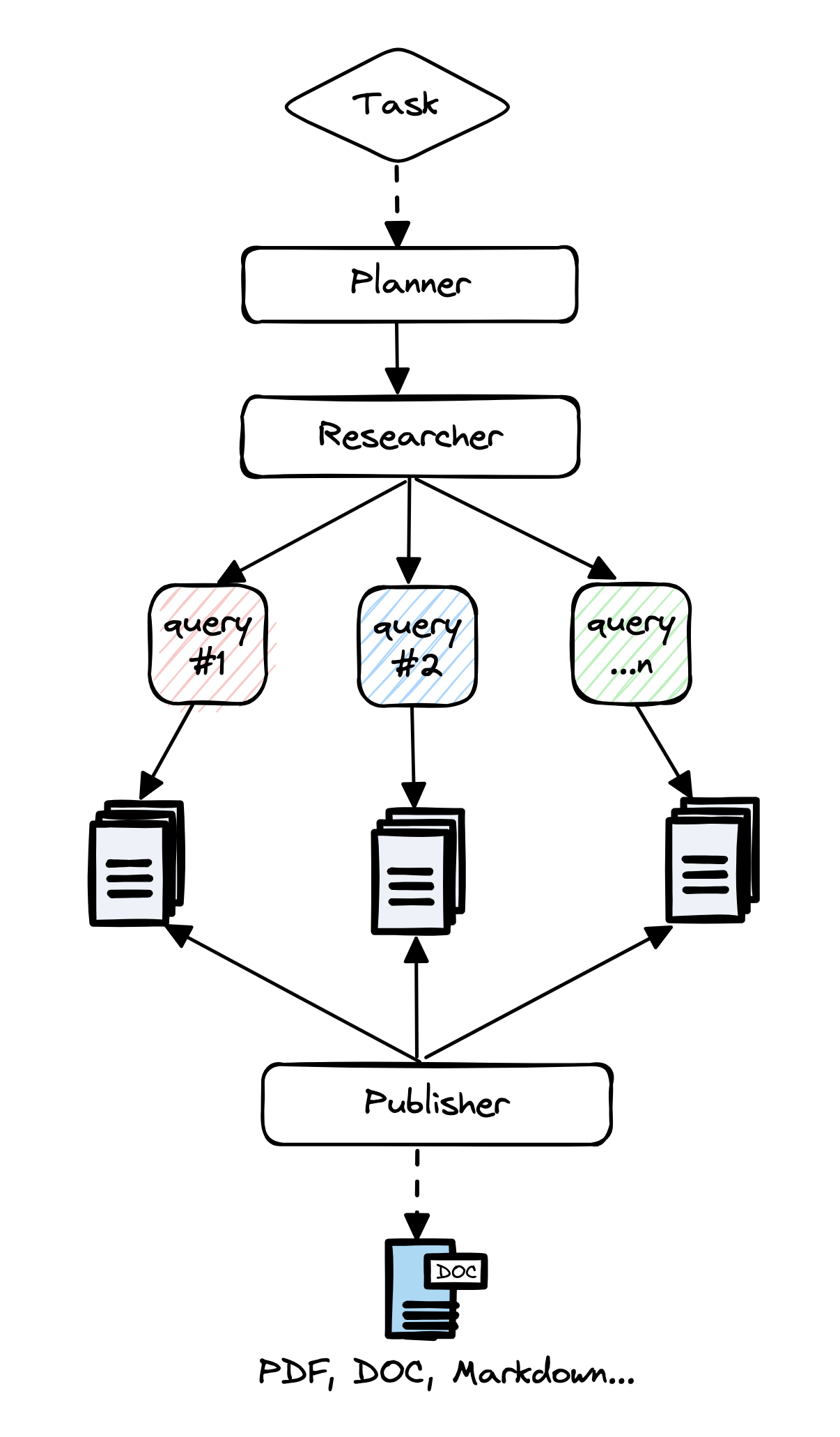
Every prompt in this system is meticulously hand-tuned through “prompt engineering.” Evaluation relies on subjective eyeballing of the outputs, resulting in inconsistent report quality. It is beautiful when it worked.
Untrained: Finite State Machine (FSM)
To boost report quality, engineers added complexity to the DAG approach. Rather than a single-pass process, they introduced structural patterns like reflexion (Shinn et al, 2023) and self-reflection, where the LLM reviews and refines its own output. This transforms the simple DAG into a finite state machine (FSM), with LLMs partly guiding state transitions.
This illustration from Jina.ai exemplifies the approach:
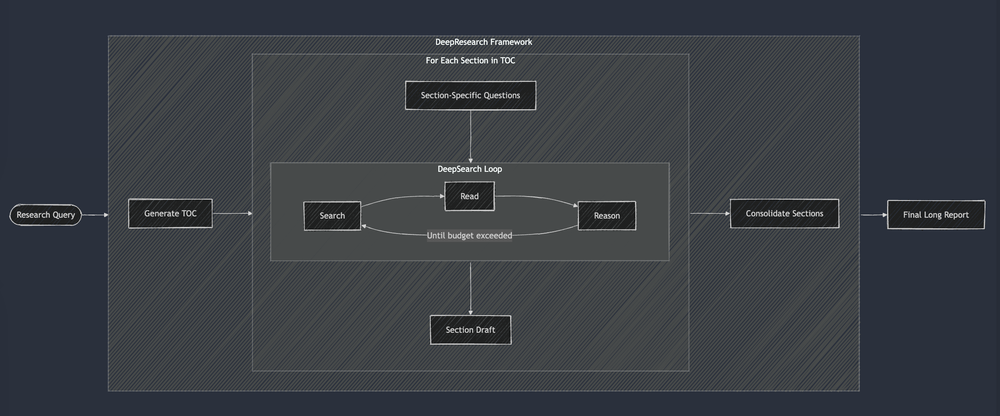
Like the DAG method, every prompt is hand-crafted, and evaluations remain subjective. Report quality continues to vary widely as the system is hand tuned.
Trained: End to End
The shortcomings of earlier methods—haphazard prompt engineering and a lack of measurable evaluation metrics—prompted a shift. Stanford’s STORM [Shao et al, 2024] addressed these issues by optimizing the system end to end using DSPy (Khattab et al, 2023).
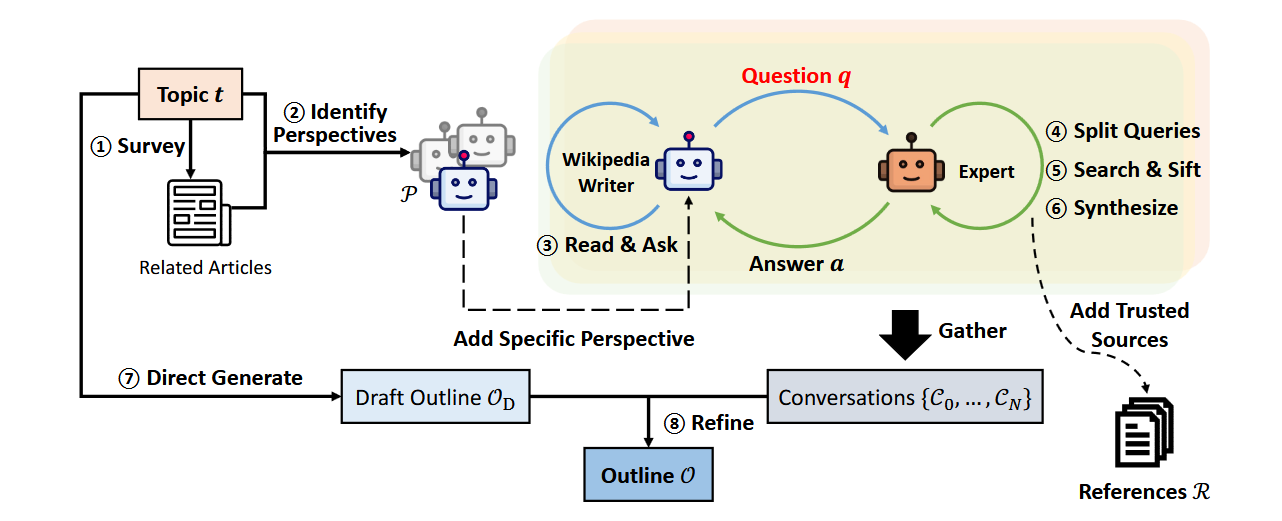
The result? STORM generates reports rivaling Wikipedia articles in quality.
Trained: Large Reasoning Model
Advances in LLM reasoning capabilities have made large reasoning models a compelling option for Deep Research. For instance, OpenAI described how it trained its Deep Research model below. Note that OpenAI used LLM-as-a-judge and evaluation rubrics to grade the outputs.

Google’s Gemini and Perplexity’s chat assistants also offer “Deep Research” features, but neither has published any literature on how they optimized their models or systems for the task or any substaintial quantitative evaluations. However, the product manager of Google’s Deep Research did mention during a podcast interview that they “have special access per se. It’s pretty much the same model (Gemini 1.5). We of course have our own, uh, post-training work that we do”. We will make an assumption that the fine-tuning work done is non-substantial. Meanwhile, xAI’s Grok excels at report generation, though it does not seem to search beyond two iterations - few times for the outline sections, and few times per section.
Competitive Landscape
We’ve developed a conceptual map to evaluate the Deep Research capabilities of various popular services. The vertical axis measures the depth of research, defined by how many iterative cycles a service performs to gather additional information based on prior findings. The horizontal axis assesses the level of training, ranging from hand-tuned systems (e.g., those using manually crafted prompts) on one end to fully trained systems leveraging machine learning techniques on the other. Examples of trained systems include:
OpenAI Deep Research: Optimized specifically for research tasks through reinforcement learning.
DeepSeek: Trained for general reasoning and tool use, adaptable to research needs.
Google Gemini: Instruction fine-tuned large language models (LLMs), trained broadly but not specialized for research.
Stanford STORM: A system trained to streamline the entire research process end-to-end.
This framework highlights how different services balance iterative research depth with the sophistication of their training approaches, offering a clearer picture of their Deep Research strengths.

Conclusion
The Deep Research landscape is evolving at breakneck speed. Techniques that flopped or weren’t widely available six months ago might now succeed. Naming conventions remain murky, adding to the confusion. Hopefully, this post clarifies the technical distinctions and cuts through the hype.
References
- Yijia Shao, Yucheng Jiang, Theodore A. Kanell, Peter Xu, Omar Khattab, Monica S. Lam (2024) Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models. Retrieved from https://arxiv.org/abs/2402.14207
- OpenAI (2025). Deep Research System Card. Retrieved from https://cdn.openai.com/deep-research-system-card.pdf
- assafelovic. (2024). GPT Researcher (Version [latest version]) [Computer software]. GitHub. Retrieved from https://github.com/assafelovic/gpt-researcher
- Jina AI. (2024). A practical guide to implementing DeepSearch/DeepResearch. Retrieved from https://jina.ai/news/a-practical-guide-to-implementing-deepsearch-deepresearch/
- Latent Space. (2024). The inventors of deep research. Retrieved from https://www.latent.space/p/gdr
@article{
leehanchung,
author = {Lee, Hanchung},
title = {The Differences between Deep Research, Deep Research, and Deep Research},
year = {2025},
month = {02},
howpublished = {\url{https://leehanchung.github.io}},
url = {https://leehanchung.github.io/blogs/2025/02/26/deep-research/}
}