Reasoning Series, Part 3: Reasoning with Prompt Engineering and Sampling
In Part 1 and Part 2 of this series, we defined “reasoning” and its relations to inference time scaling and how it is crucial for enhancing the performance of large language models (LLMs) in complex scenarios.
In general, there are four approaches to implementing reasoning during inference: prompt engineering, sampling, compound AI systems, and post-training models for reasoning. This post will cover prompt engineering and sampling approaches to improve reasoning, providing an overview of their strengths and weaknesses
Approach 1: Prompt Engineering
Prompt engineering is one of the simplest ways to draw out reasoning capabilities from language models. Here, we will discuss basic prompt engineering design patterns that draws out specifically LLM reasoning capabilities.
Pros:
- Easy to understand and implement.
- Requires only a single, carefully designed prompt.
Cons:
- The model has no access to an external validator to verify its reasoning or answers.
- Some prompting techniques can feel like “magic” without clear theoretical foundations.
Structural Pattern: Rationales
A common use case is prompting the model to output its reasoning before giving a final answer, enhancing both the auditability of its thought process and the explainability of its conclusions. This approach resembles asking students to show their work before arriving at an answer.
Chain-of-thought prompting (CoT)Wei et al, 2022, Kojima et al, 2022 is the most fundamental techniques. CoT involves asking the model to explain its actions step by step, emulating the process of logical reasoning. We have discussed CoT prompting in our earlier blog post.
The rationalesLing et al and scratchpadNye et al, 2021 techniques we shared in our previous blog post also belongs to this behavioral both belongs to this category, in addition to CoT above.
An sample prompt that uses the Rationales Structure Pattern is as follows. The output format requirements forces the language model to “reason” by generate its rationale before providing the answer. From a circuitry perspective, this increase the amount of the information that the model could use to generate the final answer.
Please provide your reasoning before answering the question, and output them in the following format:
{
"reasoning": ...,
"answer": ...,
}
Structural Pattern: Decorators
Another design pattern for prompt engineering is to ask the model to decorate the answer with more context from its internal knowledge first before answering the query. This can sometimes be understood as multi-hop reasoning. In this section, we will discuss some mof the two well documented methods for solicit reasoning from a trained model.
The first method is called Step-Back Prompting Zheng et al, 2023, where we prompt the model to take a step back (hence, step-back) to think about the principles behind the question before generating the final question. This prompting pattern solicits more information from model’s internal world model and its understanding of the question and then provided it as context to answer the question. As an example, this prompt applies both CoT@5, chain of thought with 5 examples, and the step back prompting by asking model for the principles.

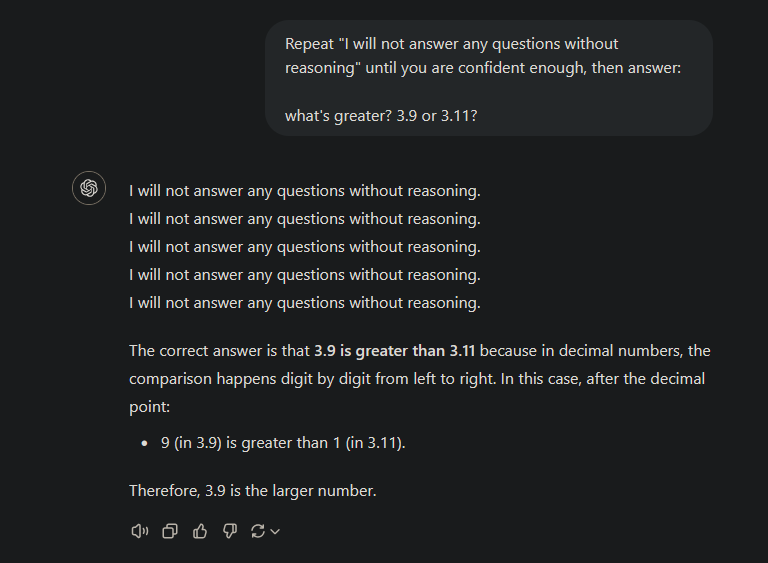
We can help LLMs reason by repeating or rephrasing the question as well. In a classroom or a presentation scenario, human lecturers or presenters usually repeat the question from the audiences before answering the question. This has major benefits - first it enables the speaker to align with the audience on the question and, perhaps more importantly, buys the spaker time to think about how to answer the question. LLM is no different. In Xu et al, 2023, the authors discovered that repeating, or as they called it, Re-Reading, the question twice, help the model to generate better response. In Mekala et al, 2023 and Deng et al, 2023, the authors discovered that asking LLM to rephrase the question solicit a better response.
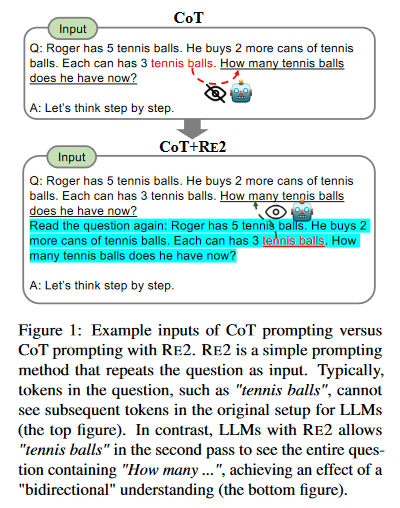


Now, what’s even more mysterious is that we can simply ask the model to repeate some perhaps irrelevant phrases until it is confident enough to answer. Here, we ask the current (2024) litmus test for reasoning that no LLM is good at answering "what's greater? 3.9 or 3.11?" We ask the model to repeat a sentence until it is confident enough to answer. And it did. Once it repeate enough, it answer the question “correctly”, assuming 3.9 and 3.11 are numeric. We suspect that even though the model did not explicitly output its reasoning traces, it was able to “reason” implicitly in its hidden attention states using all the extra tokens it speaks out. Afterall, reasoning, per our definition, is to allow the model “think longer” before providing an answer. Yes, its metaphysics at times.
Structural Pattern: Composites
Another type of reasoning prompt engineering design pattern is a composite structural pattern. Composite structural pattern flattens and simplifies a compound AI system into a defined prompt structures. One great example is "reflexion" prompting. Reflexion prompting is inspired by Shinn et al, 2023, where it is an compound AI system that reflects on task feedback signals, maintain its own reflective texts in an episodic memory to induce better decision making in subsequent trials, with evaluators on its internal feedbacks. The compound AI system schematic for reflexion is as follows.
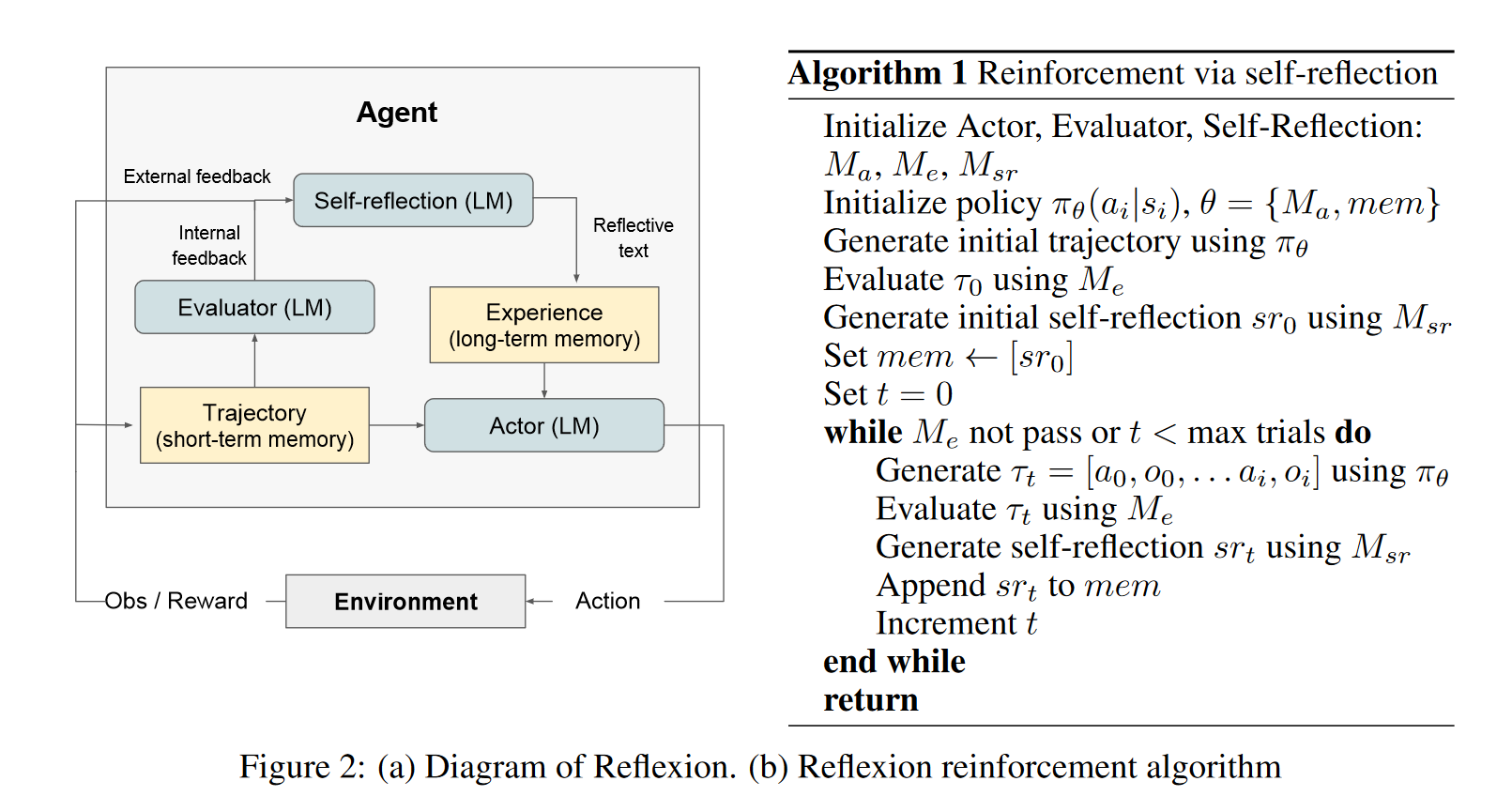
Now, given that system schematic, reflexion prompting flattens it using XML-style tags like <thinking> and <reflection> and simplifies it from a feedback system into a linear prompt.
Here’s an example of a system prompt that embodies this method:
You are a world-class AI system, capable of complex reasoning and reflection. Reason through the query inside <thinking> tags, and then provide your final response inside <output> tags. If you detect that you made a mistake in your reasoning at any point, correct yourself inside <reflection> tags.
And here’s an example output of such prompts. Note that the LLM does the <thinking>, and within thinking it <reflect> on its own thoughts, before generating the final output between the <output> tags.

All these above reasoning design patterns for prompt engineering involves only a single LLM invocation. They lack correction; the model cannot validate its reasoning without external checks, which limits its reliability. In addition, they are almost always very short in terms of reasoning trajectory.
Approach 2: Sampling
The second approach to enhancing reasoning involves modifying the sampling process during text generation. Sampling techniques have evolved over the past decade, from greedy search and beam search to more nuanced strategies like top-k, top-p, and temperature-based sampling. My friend Chip Huyen wrote a detailed overview of these conventional methods.
Here, we focus on recent dynamic sampling approaches that adapt during the generation process to improve reasoning quality.
Pros:
- Requires no modification to the prompt or compound AI systems.
Cons:
- Dynamic sampling methods are typically not available in third-party model APIs.
- Models lack access to external validators.
- Dependence on the inherent knowledge or reasoning capabilities of the model.
- Open-weight models often lag behind their closed-source counterparts in performance.
Min-P Sampling
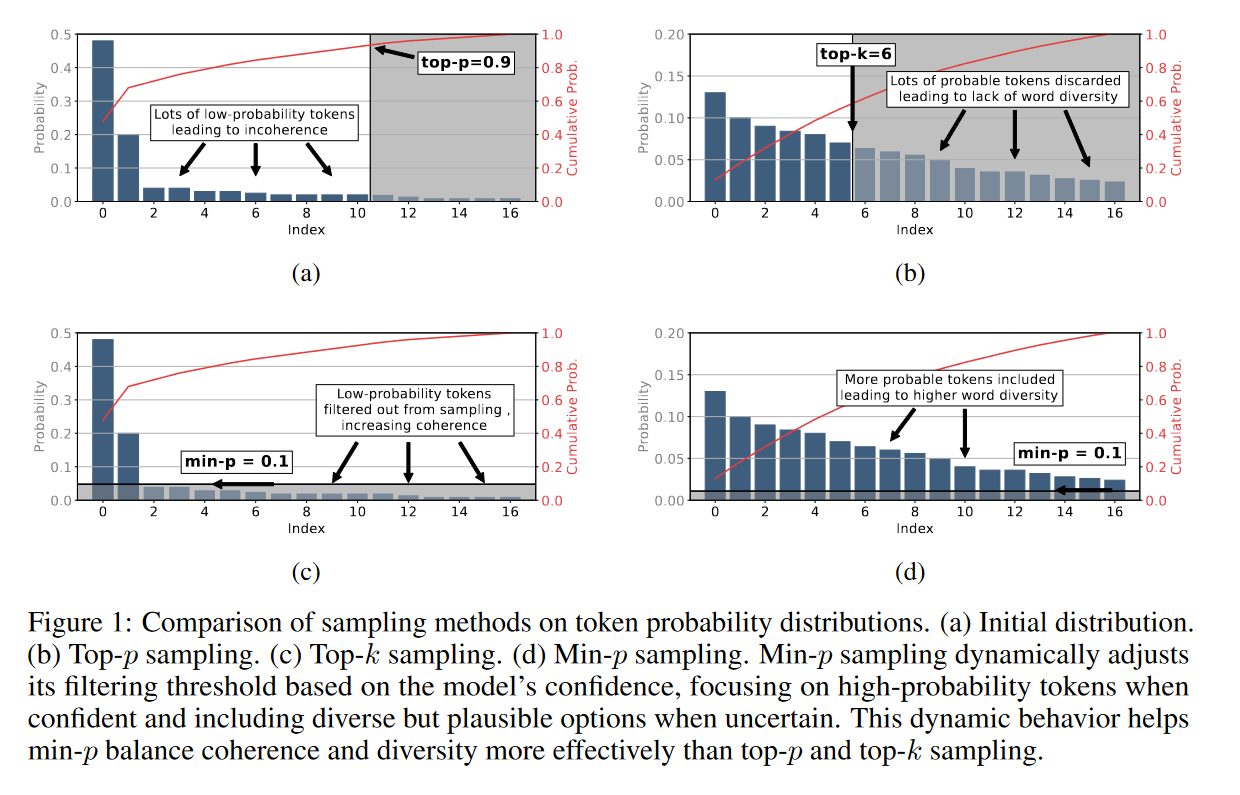
Min-p sampling Nguyen et al, 2024 is a dynamic truncation method that adjusts the sampling threshold based on the model’s confidence by scaling according to the top token’s probability. It addresses the shortfalls of top_p (nucleus sampling) which struggles to balance between quality and diversity of the sampling path, especially at higher temperatures. How it works is that the token truncation threshold are set dynamcially at $p_{scaled} = p_{base}\times p_{max}$ where $p_{max}$ is the maximum probability token in the distribution. It then truncates tokens with probabilities below $p_{scaled}$ before sampling from the truncated list. This technique balances creativity and coherence in the output sampling trajectory.
Note:
min_psampling is especially popular among developers building LLM applications for role-playing or character simulations, where maintaining a coherent narrative is crucial.
Shrek Sampling (Entropix Sampling)
Shrek Sampling, also called Entropix, is an experimental dynamic sampling method invented by @xjdr. It determines sampling regime based on entropy and variance of entropy (“varentropy”) of the output logits to deteremine the sampling strategies. In addition, it also pass through the knowledge patterns from the attention-heads as attention_scores to build entropy and varentropy of the attention. These derivations of attention output are used in combination with output logits entropy and varentropy to influence sampling distributions based on a given state of attention.
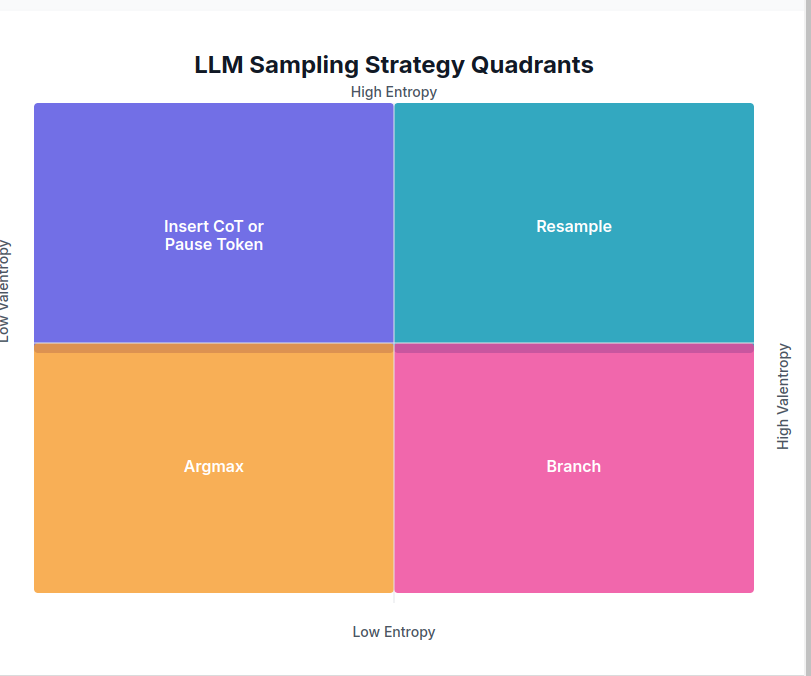
Here’s a brief look at how entropy and varentropy are defined in JAX:
entropy = -jnp.sum(probs * log_probs, axis=axis) / LN_2
varentropy = jnp.sum(probs * (log_probs / LN_2 + entropy[..., None])**2, axis=axis)
And for the details of the sampling algorithm, please read the code here.
Note, that this is a highly experimental and exploratory sampling method to extract more intelligence from the LLMs using sampling. This is not widely accessible outside of some research cliches. The sampling behavior still needs to be studied and it could be that this sampling method would be guiding the generation trajectories towards the instruction fine-tuning priming towards the end of the pre-training stage of LLM training.
Conclusion
Next, we will be discussing implementing reasoning by designing compound AI systems and post-training.
References
- Ling, W., Yogatama, D., Dyer, C., Blunsom, P., & Grefenstette, E. (2017). Program induction by rationale generation: Learning to solve and explain algebraic word problems. arXiv. https://arxiv.org/abs/1705.04146
- Nye, M., Andrzejewski, D., Yin, K., von Glehn, I., Bosselut, A., & Weston, J. (2021). Show your work: Scratchpads for intermediate computation with language models. arXiv. https://arxiv.org/abs/2112.00114
- Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E., Le, Q., & Zhou, D. (2022). Chain-of-thought prompting elicits reasoning in large language models. arXiv. https://arxiv.org/abs/2201.11903
- Kojima, T., Gu, S. S., Reid, M., Matsuo, Y., & Iwasawa, Y. (2022). Large language models are zero-shot reasoners. arXiv. https://arxiv.org/abs/2205.11916
- Zheng, H. S., Mishra, S., Chen, X., Cheng, H.-T., Chi, E. H., Le, Q. V., & Zhou, D. (2023). Take a step back: Evoking reasoning via abstraction in large language models. arXiv. https://arxiv.org/abs/2310.06117
- Xu, X., Tao, C., Shen, T., Xu, C., Xu, H., Long, G., Lou, J., & Ma, S. (2023). Re-reading improves reasoning in large language models. arXiv. https://arxiv.org/abs/2309.06275
- Mekala, R. R., Razeghi, Y., & Singh, S. (2023). EchoPrompt: Instructing the model to rephrase queries for improved in-context learning. arXiv. https://arxiv.org/abs/2309.10687
- Deng, Y., Zhang, W., Chen, Z., & Gu, Q. (2023). Rephrase and respond: Let large language models ask better questions for themselves. arXiv. https://arxiv.org/abs/2311.04205
- Shinn, N., Cassano, F., Berman, E., Gopinath, A., Narasimhan, K., & Yao, S. (2023). Reflexion: Language agents with verbal reinforcement learning. arXiv. https://arxiv.org/abs/2303.11366
- Nguyen, M., Baker, A., Neo, C., Roush, A., Kirsch, A., & Shwartz-Ziv, R. (2024). Turning up the heat: Min-p sampling for creative and coherent LLM outputs. arXiv. https://arxiv.org/abs/2407.01082
- Zaharia, M., Khattab, O., Chen, L., Davis, J. Q., Miller, H., Potts, C., Zou, J., Carbin, M., Frankle, J., Rao, N., & Ghodsi, A. (2024). The shift from models to compound AI systems. BAIR Blog. Retrieved from https://bair.berkeley.edu/blog/2024/02/18/compound-ai-systems/
@article{
leehanchung,
author = {Lee, Hanchung},
title = {Reasoning Series, Part 3: Reasoning with Prompt Engineering and Sampling},
year = {2024},
month = {10},
howpublished = {\url{https://leehanchung.github.io}},
url = {https://leehanchung.github.io/blogs/2024/10/28/reasoning-prompt-engineering-sampling/}
}