Reasoning Series, Part 1: Understanding OpenAI o1
OpenAI released the long-awaited OpenAI o1-preview on September 12, 2024. This model was previously known as Q* in 2023 and superceded by Project Strawberry in 2024. In this first installment of the Reasoning series, we aim to separate rumors from facts about how the OpenAI o1 model works and validate our conjectures through experiments. This will help users better understand and utilize OpenAI o1.
Reasoning
In Thinking, Fast and Slow, Daniel Kahneman defined System 1 as the automatic, intuitive mode of thinking, and System 2 as the slower, more analytical mode. In the context of autoregressive language models, the usual inference process is akin to System 1 — models generate answers directly. Reasoning is System 2 thinking - models or systems takes time to deliberate to solve more complex problems.
What Is OpenAI o1?
OpenAI o1 provide models the ability to perform System 2 thinking by introducing “reasoning tokens.” This approach is similar to the Zero-Shot Chain of Thought (CoT@0) by Kojima 2022, where we prompt a model to “think step by step” before answering a question. The o1 model internalized this concept by providing a “scratchpad” Nye 2021, allowing models to reason more effectively, especially for tasks that benefit from more thinking time, measured in reasoning tokens.

For informational queries such as “What’s the capital of France?”, additional reasoning time isn’t needed. The model either knows the answer or it does not. But for complex tasks, such as coding or math problems, the ability to reason makes a significant difference. For example, DeepMind’s AlphaGo benefited from deep thinking time through Monte Carlo Tree Search (MTCS), which was especially useful for adversarial Go matches. Similarly, OpenAI o1 shines in tasks requiring structured problem-solving abilities.
In other words, instead of simply “speaking” directly like GPT-4o, the OpenAI o1 model “thinks” before it “speaks.”
Before the release of OpenAI o1-preview, speculation about how OpenAI implemented the reasoning models was rampant. People guessed about Tree of Thought (ToT Yao 2023), Graph of Thought (GoT Besta 2023), MCTS, and other search algorithms. There were even wilder ideas about continuous learning or graph-based information retrieval — a mess of research paper titles repurposed by ChatGPT and passed around the AI influencer community.
Now that OpenAI o1-preview is available, both on ChatGPT and via API, and with an official model card report, it’s time to clarify what OpenAI o1 really is.
Known Facts
OpenAI o1 is a Single Model
During an OpenAI AMA on Twitter, a researcher confirmed that OpenAI o1 is a single model, not a system or framework.
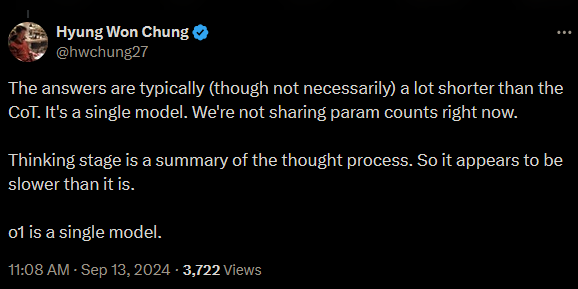
Source: Twitter
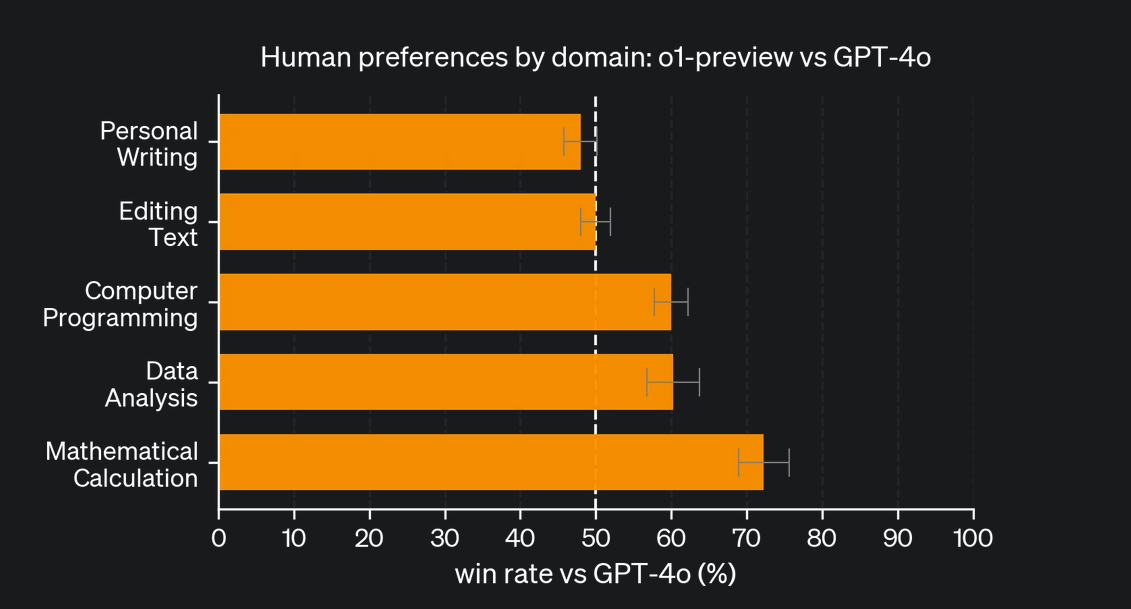
o1 does not write better than GPT-4o
The performance of o1 on open-ended tasks such as personal writing and editing text is roughly similar to GPT-4o, implying the reasoning ability does not enhance model performance uniformly across different subject areas.
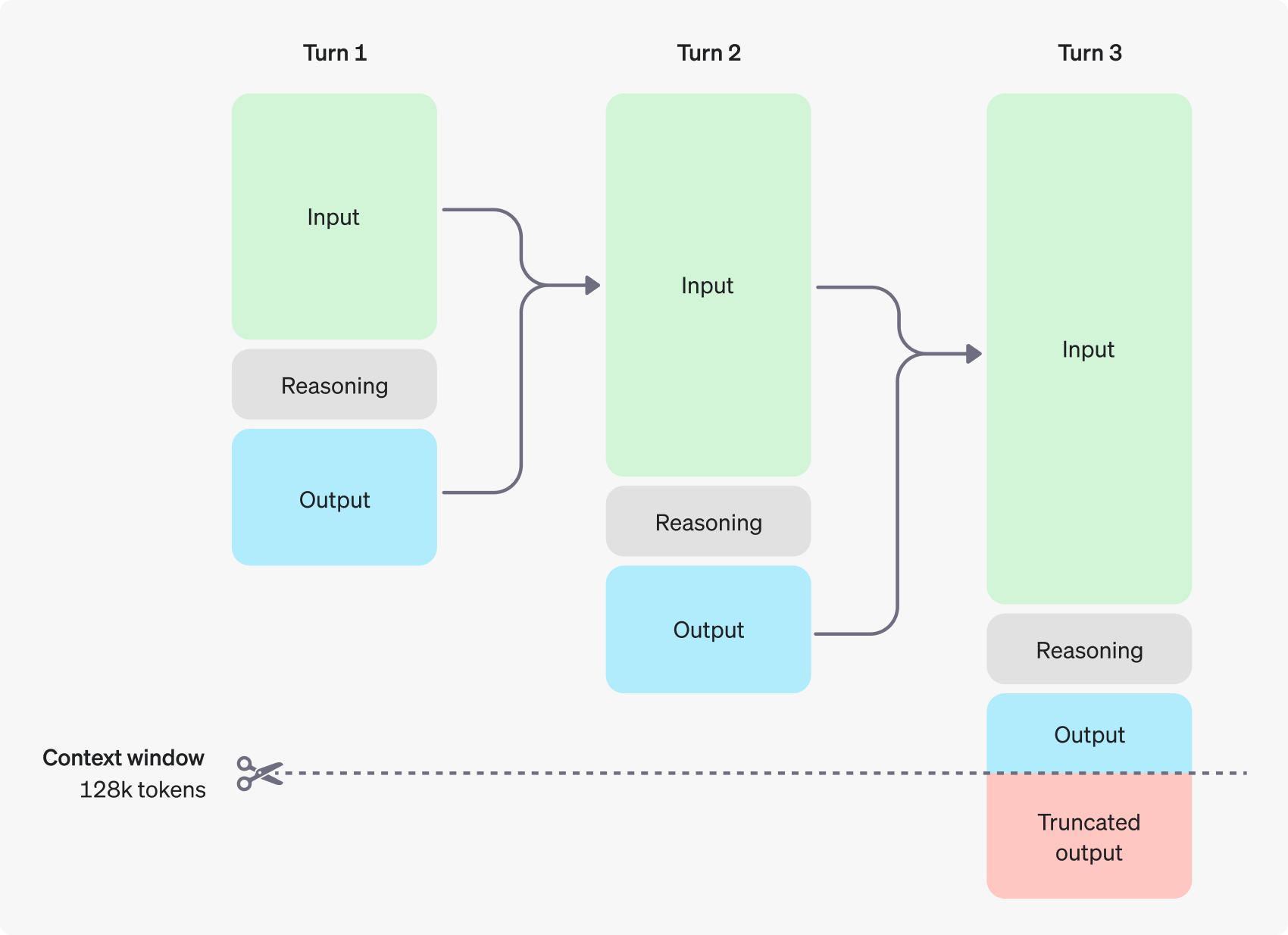
Reasoning tokens count towards the overall context length.
Reasoning tokens count toward the context window, reducing the budget available for prompt and output tokens. The o1-preview model can use 32,768 more reasoning tokens compared to the smaller o1-mini, indicating that reasoning steps are stored within the context window. However, this doesn’t necessarily rule out parallel reasoning.
Chain of thought prompting significantly impairs o1’s reasoning ability
The internal reasoning capabilities also make the model respond poorly to explicit chain-of-thought prompts like “think step by step” or “explain your reasoning.” In a simple experiment, we asked OpenAI o1: “Which is larger, 9.11 or 9.8? Answer only from 9.11 or 9.8.” While other language models often get this wrong, OpenAI o1 answered correctly around 80% of the time—as long as it had enough reasoning tokens. However, when explicitly asked to “think step by step,” accuracy dropped to 20%.
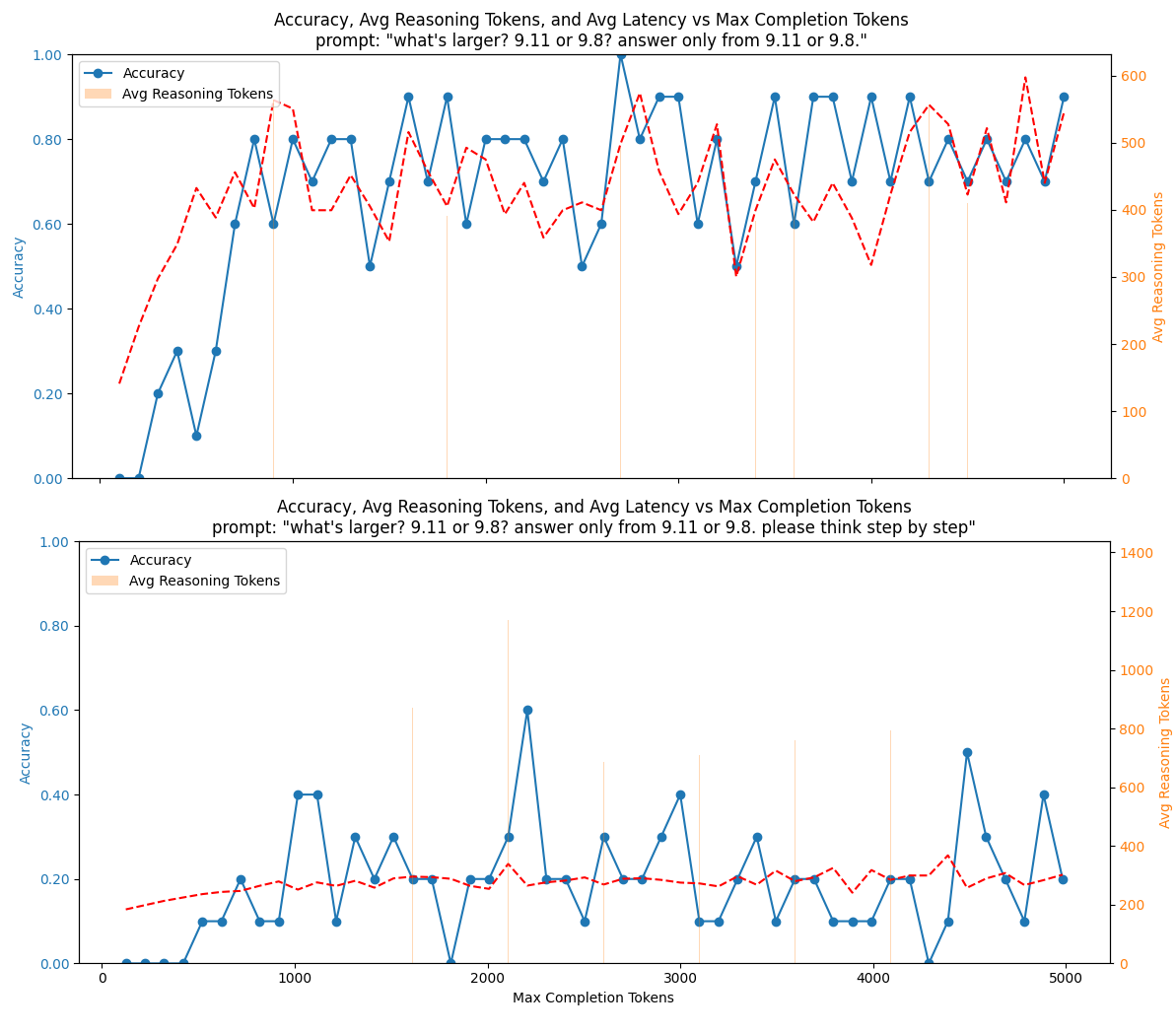
It turns out that just like humans, smart reasoning models don’t like being micromanaged. And as always, irrelevant information in retrieval-augmented generation setups can hurt reasoning performance.
Reasoning process is obfuscated
To obscure the internal reasoning process, reasoning steps are hidden from users. On ChatGPT, only the titles of reasoning steps are streamed, and their contents are summarized. For API calls, the reasoning steps are not visible, with only the count of reasoning_tokens are provided at the end of an inference.
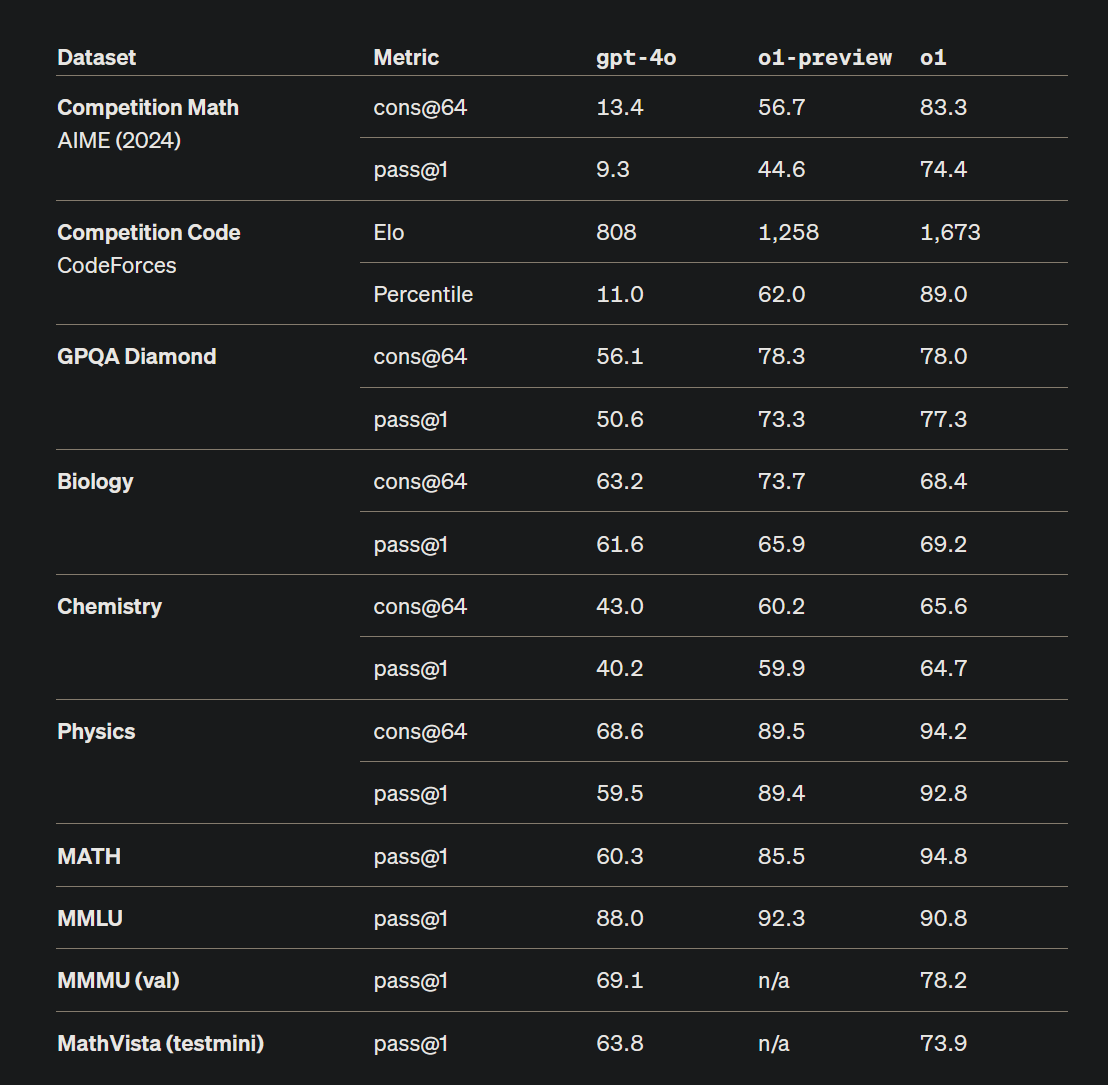
No inference-time search or sampling
The o1 model has been evaluated on tasks like Competition Math (AIME 2024) and Competition Code (CodeForces) using cons@64 (majority voting by 64 model calls) and pass@1 (success rate in one call). These metrics imply that there’s no inference-time search—meaning the model doesn’t employ strategies like Monte Carlo Tree Search or Graph of Thought Besta 2023 during reasoning. In addition, pass@1 scores should at least be equivalent or exceed cons@64 as objective oriented search should work better than repeated sampling.
Chain of thought examples does not indicate search or backtracking
OpenAI’s research blogs on Learning to Reason with LLMs and the o1 System Card provide some full Chain of Thought examples. These don’t appear to involve search or backtracking — though they may shift perspectives or re-evaluate decisions, it all happens in a forward, sequential decision making manner. This could be an artifact of OpenAI selectively disclosing its implementation details.

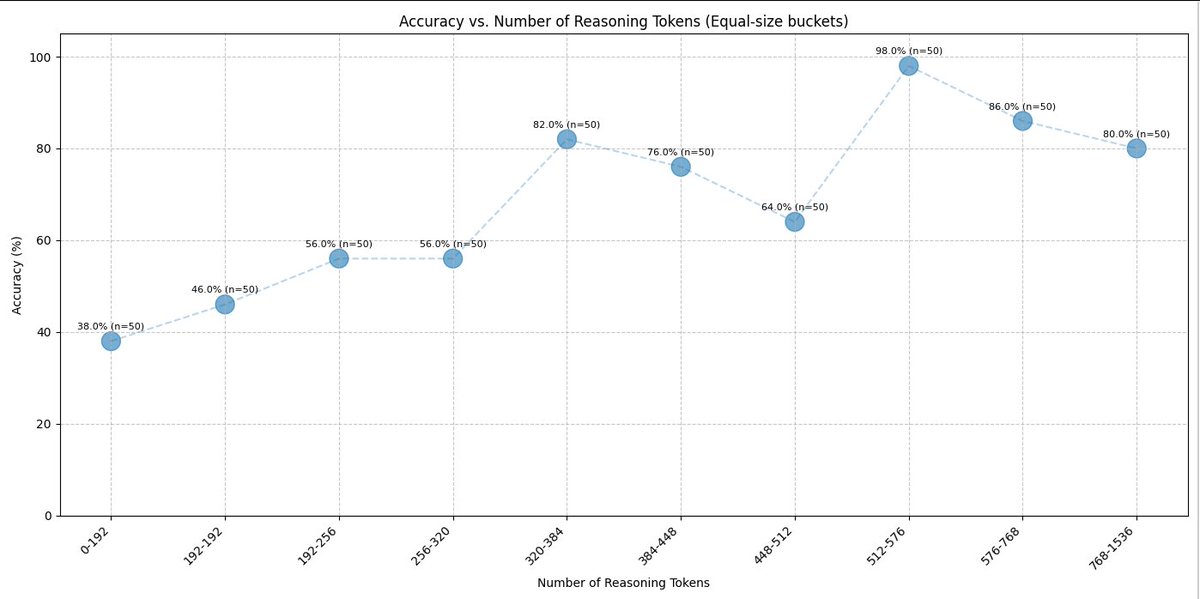
Model capabilities does not scale with reasoning tokens
Based on our naive reasoning examples, we observed that reasoning tokens exhibits U-shaped scaling. Model becomes smarter as it spend more reasoning tokens up to a threshold; model capabilities then declines as it spend even more reasoning tokens. An inversed U-shape curve.
Reasoning steps are streamed with a title with summarized content
On ChatGPT, reasoning step titles are visible while the content is dynamically summarized. So far, these titles don’t appear to be modified, suggesting limited backtracking in reasoning.
Educated Guesses
OpenAI linearized search and reasoning steps
We plotted the relationship between reasoning token and inference time using OpenAI o1 API. The API does not show specific tokens as previously mentioned, but does indicate the number of reasoning_tokens for billing purposes. To minimize the impact of pre-fill (prompts) and maximize the impact of reasoning tokens on latency, we used the above example prompt “what’s larger? 9.11 or 9.8? answer only from 9.11 or 9.8.” for short inputs and short outputs.
If, any search algorithm such as MTCS, ToT, GoT, is used and OpenAI is counting those tokens for billing purposes, the relationship between latency vs reasoning tokens would be sub-linear, i.e., we would consume a lot more tokens with only a little increase in latency. The results is plotted below, and the relationship is fairly linear, indicating that no search is used at inference time.
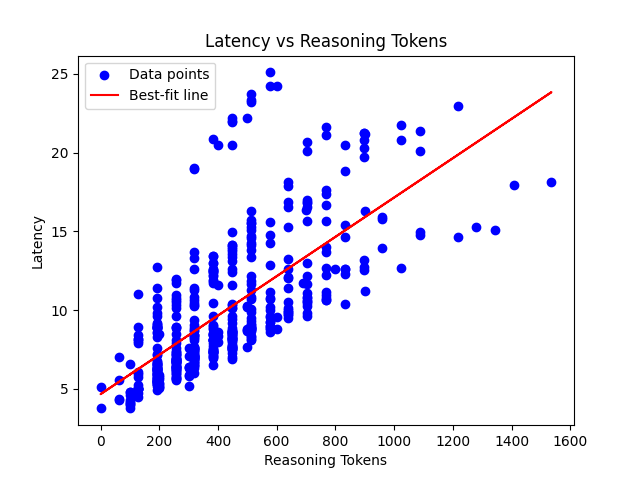
However, we do not rule out the possibility that OpenAI is up-charging the reasoning tokens and intentionally ignoring the token used in inference time search system. This seems unlikely, as scaling law favors training models to reason instead of programming models to search for reasoning.
Conclusion
This covers the initial release and understanding of OpenAI o1. In future parts of this series, we’ll delve deeper into the topic of reasoning and an attempt to replicate the functionality of o1 model. Reasoning Series, Part 2: Reasoning and Inference Time Scaling.
References and Acknowledgements
- Reuters. (2024, July 12). Exclusive: OpenAI working on new reasoning technology under code name ‘Strawberry’. Reuters. https://www.reuters.com/technology/artificial-intelligence/openai-working-new-reasoning-technology-under-code-name-strawberry-2024-07-12/
- Nye, M., Andreassen, A. J., Gur-Ari, G., Michalewski, H., Austin, J., Bieber, D., Dohan, D., Lewkowycz, A., Bosma, M., Luan, D., Sutton, C., & Odena, A. (2021). Show Your Work: Scratchpads for Intermediate Computation with Language Models. arXiv. https://arxiv.org/abs/2112.00114
- Kojima, T., Gu, S. S., Reid, M., Matsuo, Y., & Iwasawa, Y. (2022). Large Language Models are Zero-Shot Reasoners. arXiv. https://arxiv.org/abs/2205.11916
- OpenAI. (2024). Learning to reason with LLMs. OpenAI. https://openai.com/index/learning-to-reason-with-llms/
- OpenAI. (2024, September 17). OpenAI o1 system card. OpenAI. https://cdn.openai.com/o1-system-card-20240917.pdf
- Chung, H. W. [@hwchung27]. (2024). Twitter. https://x.com/hwchung27/status/1834655287934173449
- Yao, S., Yu, D., Zhao, J., Shafran, I., Griffiths, T. L., Cao, Y., & Narasimhan, K. (2023). Tree of Thoughts: Deliberate Problem Solving with Large Language Models (v2). arXiv. https://arxiv.org/abs/2305.10601
- Besta, M., Blach, N., Kubicek, A., Gerstenberger, R., Podstawski, M., Gianinazzi, L., Gajda, J., Lehmann, T., Niewiadomski, H., Nyczyk, P., & Hoefler, T. (2023). Graph of Thoughts: Solving Elaborate Problems with Large Language Models. arXiv. https://arxiv.org/abs/2308.09687
@article{
leehanchung,
author = {Lee, Hanchung},
title = {Reasoning Series, Part 1: Understanding OpenAI o1},
year = {2024},
month = {10},
howpublished = {\url{https://leehanchung.github.io}},
url = {https://leehanchung.github.io/blogs/2024/10/08/reasoning-understanding-o1/}
}