Adapt or Obsolete: The Imperative of Updating Your Priors in the Age of Scaling Compute
In the rapidly evolving fields of AI and NLP, traditional expertise can become obsolete almost overnight with the advent of compute as noted by Rich Sutton’s the Bitter Lesson. The Bitter Lesson argues that the most significant advances in AI has come from leveraging Moore’s Law for large amounts of compute and data, rather relying on specialized human-designed features or algorithms. This shift means expertise in traditional handcrafted techniques can quickly lose relevance.
This post explores the shift from hand-crafted features and parsing tasks to end-to-end deep learning models, particularly with the advent of transformers. Learn why it’s crucial to continuously update your knowledge and adapt to new technologies, or risk becoming outdated in the face of rapid advancements.
Machine Learning and Computer Vision
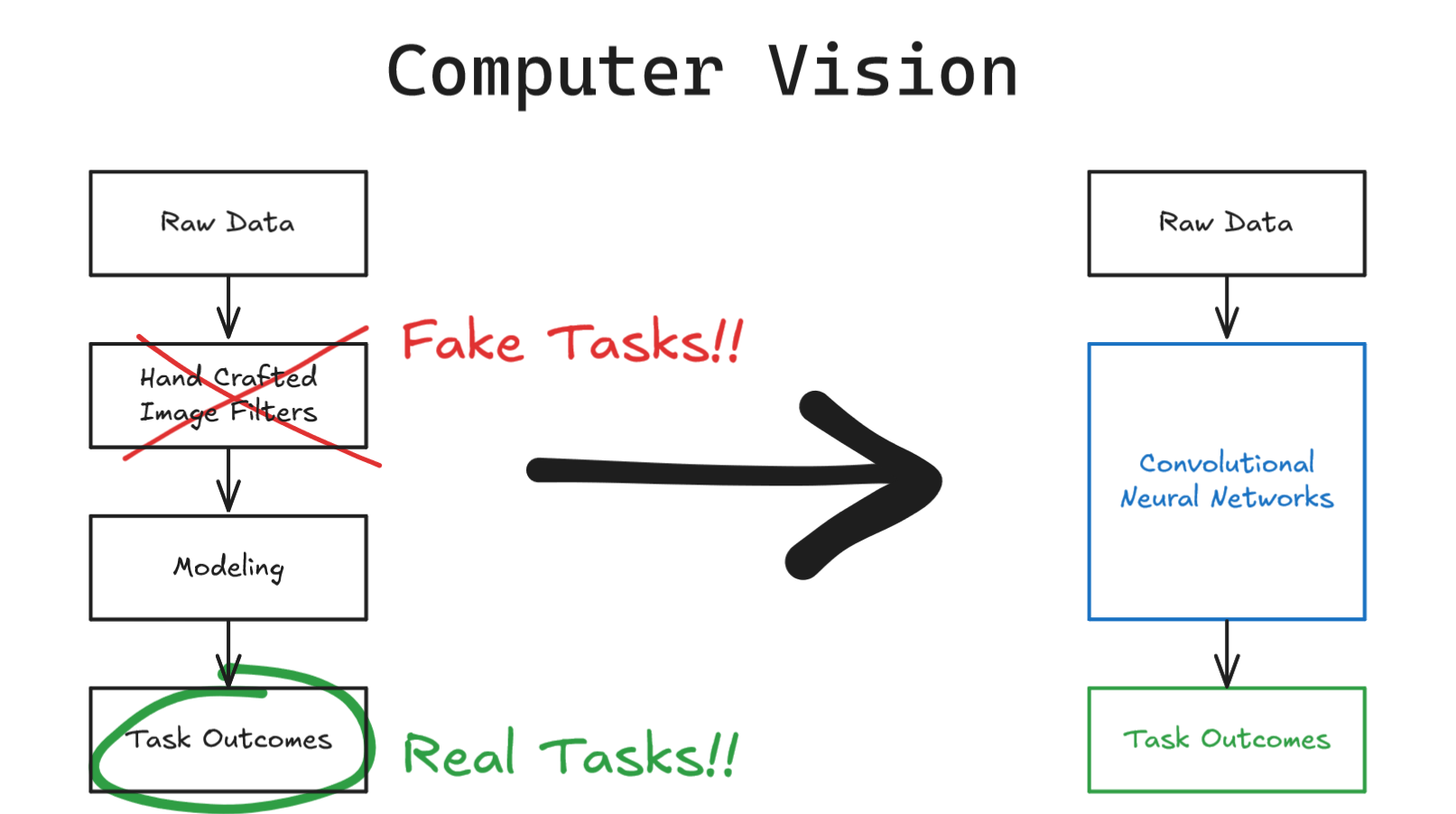
The first field of application that felt the impact of scaling compute and data is Computer Vision in 2012 with AlexNet, where instead of using hand crafted image filters, AlexNet used Convolutional Neural Networks to automatically learn all of the filters together with the model end-to-end by leveraging GPU computation and large amount of data. This kicks off the era of scaling both compute and data. The success of AlexNet inspired similar developments across other machine learning domains, leading to the replacement of handcrafted features with learned representations. Over the past decade, we have witnessed the same thing happening to traditional machine learning, where hand-crafted features are now being replaced by learned features end-to-end using deep neural networks at recommendation systems and search engines.
Natural Language Processing (NLP)
NLP is a field that studies natural language tasks. NLP encompasses tasks like machine translation, question answering, and summarization, all of which have been transformed by deep learning, particularly large language models. As a result, a lot of traditional NLP expertise in conducting the intermediary steps such as various forms of parsing and classification has become obsolete.
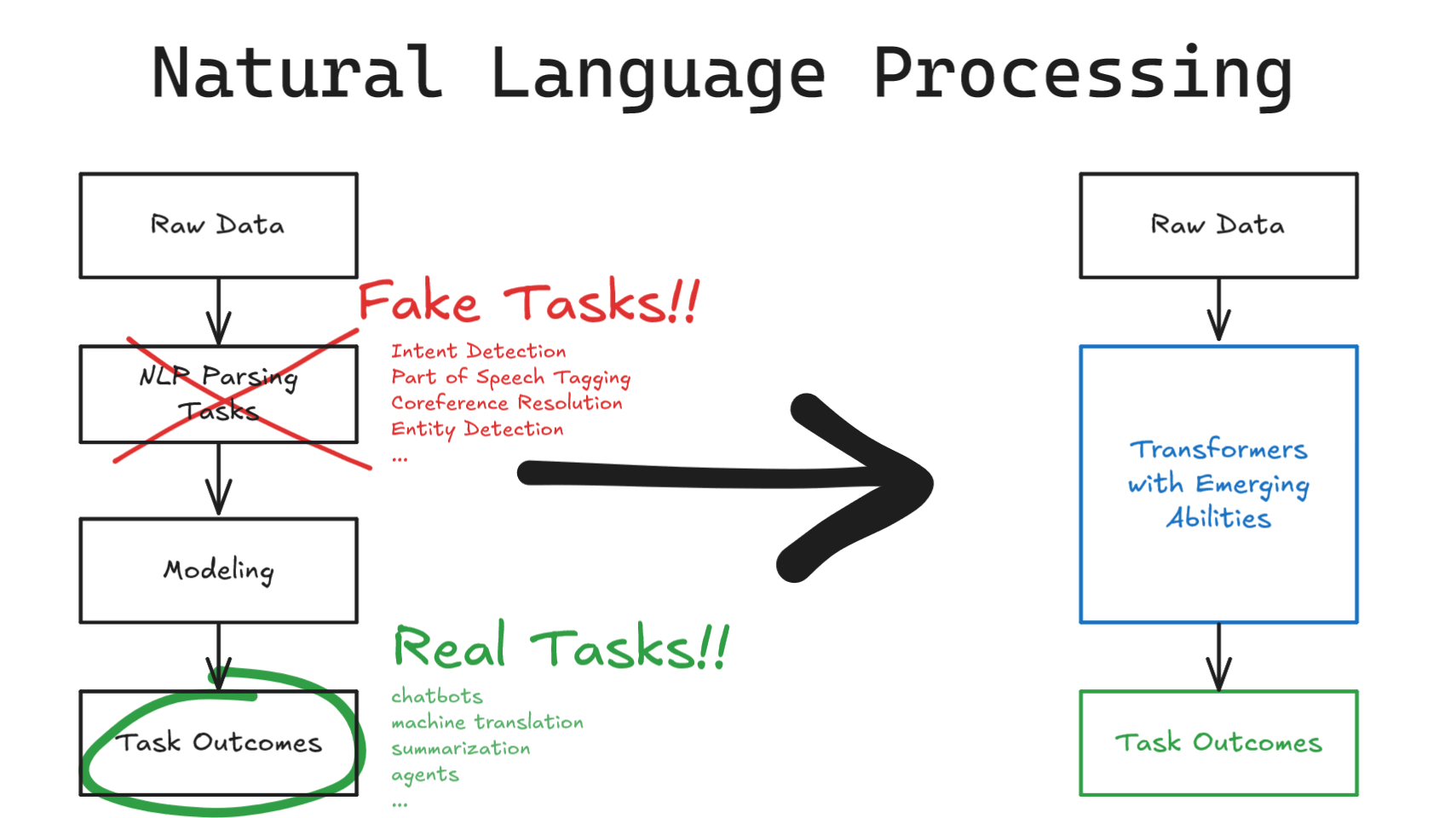
Back in 1999, NLP focused heavily on parsing tasks, such as coreference resolution, n-grams, entity extraction, etc. These tasks produced inputs for downstream tasks like question answering, summarization, and machine translation. This was similar to the early days of machine learning, where practitioners spent significant time engineering features to create and validate new data representations. These features were then used by downstream models to achieve the final task.

Deep learning changed all of this. Feature engineering, which created intermediate steps, has gradually been replaced by deep neural networks where the network learns the features automatically. Instead of using regression models or boosted trees, we now use neural networks to generate representations and learn the transformations between them.

The power of neural networks extended to NLP with the introduction of transformer models. As evidenced by the third edition of the textbook on NLP, many intermediate parsing tasks are now obsolete. Expertise in those tasks is no longer relevant to achieving the end result.
Most preprocessing techniques that generated intermediate features have also become irrelevant. With internet-scale data and deep neural networks, achieving downstream tasks no longer requires the previous parsing steps. The neural network covers everything from end to end, similar to what we see in modern machine learning workflows. Instead of extracting entities, matching pronouns, parsing verbs, and then writing a summary, we can now ask large language models (LLMs) to generate the entire result automatically. All of these intermediate steps are learned rather than hand-crafted. It echoes an old adage in machine learning: “Every time I fire a linguist, the performance of the speech recognizer goes up” – Frederick Jelinek.
Artifacts of End-to-End Learning in NLP
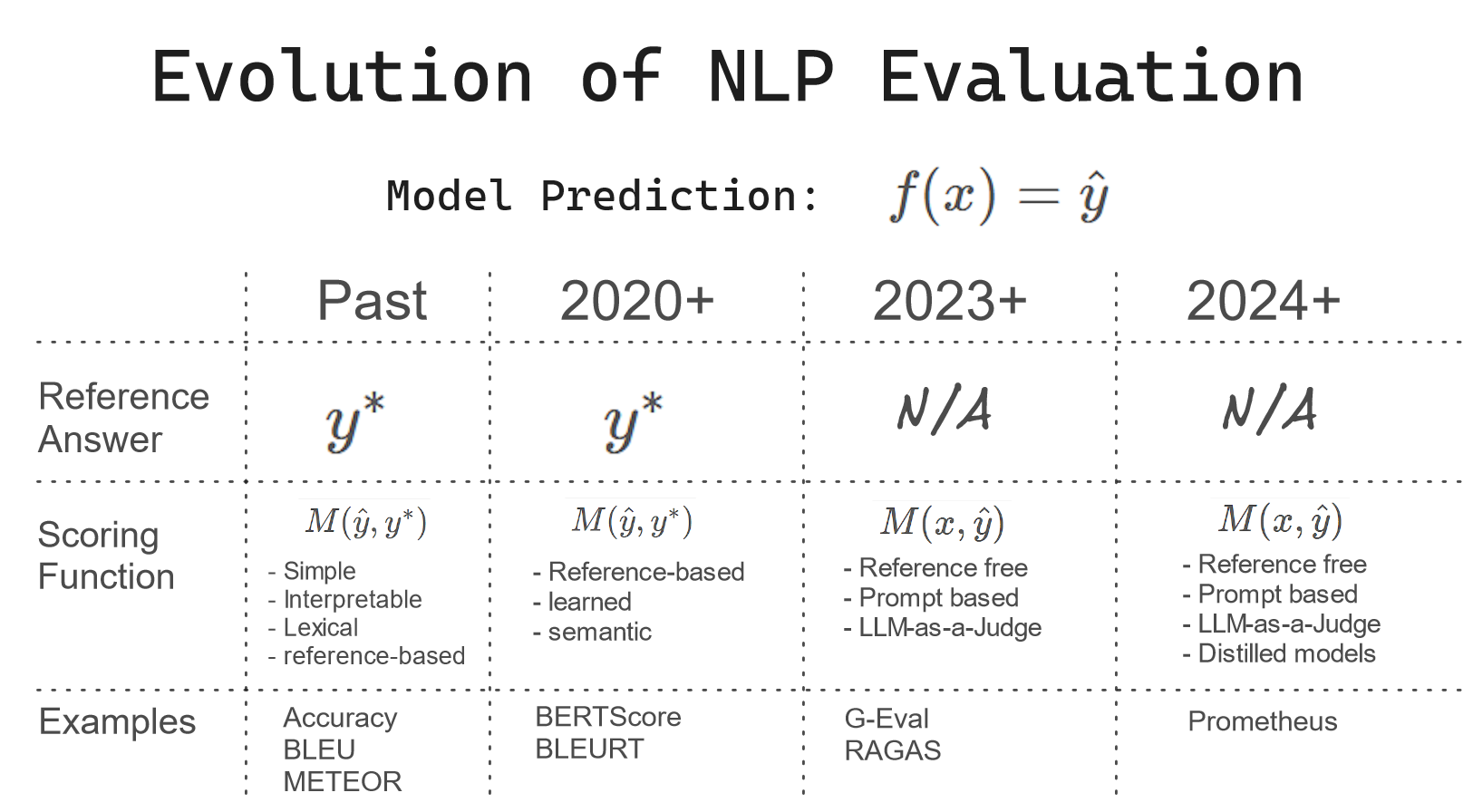
One artifact of this revolution in NLP since the introduction of transformers is that metrics for most end tasks are still defined in their task-specific ways. For instance, question answering is still measured by its specific metrics like Exact Match and F1 Score for statistical heuristics and Faithfulness for quality based metrics, and summarization by another set of standards such as ROUGE for statistical heuristics evaluations and Coherence, Consistency, Fluency, and Relevance for quality based metrics. The metrics haven’t yet unified, while the underlying text generation models have. To complicate matters, some newly published papers define metrics with unconventional names that aren’t traditionally used across fields. For example, RAGAS — a paper proposing a framework to evaluate retrieval-augmented generation (RAG) tasks — uses non-standard metrics to measure information retrieval, while using different ones for question answering. This creates confusion, especially for new entrants to the field and non-technical stakeholders.
In the meanwhile, evaluation methodologies have been evolving at a rapid pace as models become more powerful as a result of scaling compute and data. Historically, the field of NLP used a lot of heuristics-based statistical metrics such as Exact Match for Question Answering, ROUGE for Summarization, and METEOR for Machine Translation. After the invention of BERT models, we largely moved to model-based approaches such as BERTScore.
And now, with even more powerful large language models, we are moving towards the world of using LLM-as-a-Judge for evaluations. In addition, LLMs are rapidly being adopted as reward models to further improve future LLMs. This rapid change of pace signifies the importance of updating your priors to staying up to date.
Future Directions
Going forward, we are witnessing a similar evolution in computer vision (CV) with transformers. Take visual question answering (VQA) as an example. VQA is a task that allows users to ask questions about an image or a document image (e.g., PowerPoint, PDF). Traditionally, this required multiple steps and systems: an OCR model to extract text, object detection to identify objects and their relative positions, and sometimes even chunking and indexing information into a search system, like retrieval-augmented generation. Only then could text-based question-answering techniques be applied. But now, in 2024, we have new experimental models like ColPali that enable end-to-end VQA for intelligent document processing, making traditional document OCR possibly obsolete.
Conclusion
Suddenly, experts from the last decade now have knowledge that has been invalidated. This happens at breakneck speed in AI/ML as we exponentially scale both data and compute. Generative — originally defined in statistics as modeling $p(x)$ — now refers to generating text, images, or videos, showing how far the engineering reality has deviated from its origins.
Therefore, it’s crucial to continue updating your priors. Stay hands-on, be an infovore with strong beliefs but weakly held. The alternative is waking up one day to find that your expertise is no longer applicable in the ever-changing technological landscape.
References and Acknowledgements
- Sutton, R. (2019, March 13). The bitter lesson.
- Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). ImageNet classification with deep convolutional neural networks., Advances in neural information processing systems 25 (NIPS 2012)
- Girshick, R. (2024, June). The parable of the parser. CVPR 2024 CV 20/20: A Retrospective Vision, CVPR 2024, Seattle, WA.
- Wikipedia contributors. (n.d.). Frederick Jelinek. Wikipedia. Retrieved October 6, 2024
- Chin-Yew Lin. 2004. ROUGE: A Package for Automatic Evaluation of Summaries. In Text Summarization Branches Out, pages 74–81, Barcelona, Spain. Association for Computational Linguistics.
- Alexander R. Fabbri, Wojciech Kryściński, Bryan McCann, Caiming Xiong, Richard Socher, and Dragomir Radev. 2021. SummEval: Re-evaluating Summarization Evaluation. Transactions of the Association for Computational Linguistics, 9:391–409.
- Esin Durmus, He He, and Mona Diab. 2020. FEQA: A Question Answering Evaluation Framework for Faithfulness Assessment in Abstractive Summarization. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 5055–5070, Online. Association for Computational Linguistics.
- Es, S., James, J., Espinosa-Anke, L., & Schockaert, S. (2024). RAGAS: Automated evaluation of retrieval augmented generation. arXiv. https://arxiv.org/abs/2401.12345
- Satanjeev Banerjee and Alon Lavie. 2005. METEOR: An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments. In Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, pages 65–72, Ann Arbor, Michigan. Association for Computational Linguistics.
- Zhang, T., Kishore, V., Wu, F., Weinberger, K. Q., & Artzi, Y. (2020). BERTScore: Evaluating text generation with BERT. arXiv. https://arxiv.org/abs/1904.09675
- Sellam, T., Das, D., & Parikh, A. P. (2020). BLEURT: Learning robust metrics for text generation. arXiv. https://arxiv.org/abs/2004.04696
- Faysse, M., Sibille, H., Wu, T., Omrani, B., Viaud, G., Hudelot, C., & Colombo, P. (2024). ColPali: Efficient document retrieval with vision language models. arXiv. https://arxiv.org/abs/2406.12345
- Lee, H. (2024, August). LLM-as-a-Judge: Rethinking model-based evaluations in text generation. Lee Hanchung’s Blog. https://leehanchung.github.io/blogs/2024/08/11/llm-as-a-judge/
- Zhang, L., Hosseini, A., Bansal, H., Kazemi, M., Kumar, A., & Agarwal, R. (n.d.). Generative verifiers: Reward modeling as next-token prediction. arXiv. https://arxiv.org/abs/2408.15240
@article{
leehanchung,
author = {Lee, Hanchung},
title = {Adapt or Obsolete: The Imperative of Updating Your Priors in the Age of Scaling Compute},
year = {2024},
month = {10},
howpublished = {\url{https://leehanchung.github.io}},
url = {https://leehanchung.github.io/blogs/2024/10/06/update-your-priors/}
}