Frameworks for LLMs and Compound AI Systems through the Lens of 50 Years of Semiconductor History
The release of OpenAI’s GPT-o1 marks the beginning of the era of compound AI systems (transformers as a computational model). These new systems introduce reasoning abilities during inference, moving away from the previous paradigm of optimizing parametric weights during pre-training or post-training. This shift introduces a new phase for LLM systems with markup languages like LangChain Expression Language (LCEL) and DSPy, and prompt optimization frameworks such as ProTeGi, PromptBreeder, DSPy, TextGrad, and Sammo.
The Unlikely Path
There are two potential future paths. First, improvements in LLM systems at inference-time could follow the trajectory of automated machine learning (AutoML) or neural-network architecture search (NAS), leading to a bleak future for prompt optimization. AutoML uses search algorithms to find the best model and hyperparameters for supervised learning, while NAS searches for the optimal neural network architecture for a given task. Although both AutoML and NAS sound appealing on paper, they have so far been underwhelming in terms of contributions or adoption by industry practitioners. The optimized hyperparameters are also fairly underwhelming compared to hand-tuned models by experts. This thinking, however, is rooted in old-school ML paradigms and does not apply well to foundation models, which represent a step-change in AI capabilities. LLMs are not just another iteration of AI — they represent a transformative change with their meta learning capabilities, unlike the narrow and passive AI/ML models we have seen before.
Likely Path
The second, and more likely progression, is that the era of compound AI systems has just begun. We should expect the development of ecosystems to scale these capabilities. As Andrej Karpathy noted, the advancement of LLMs will introduce a whole new computing paradigm. The transformer as a computation model positions the LLM as the CPU of AI systems, interfacing and connecting to various tools: peripheral devices, file systems, classical computer tools, the internet, etc.
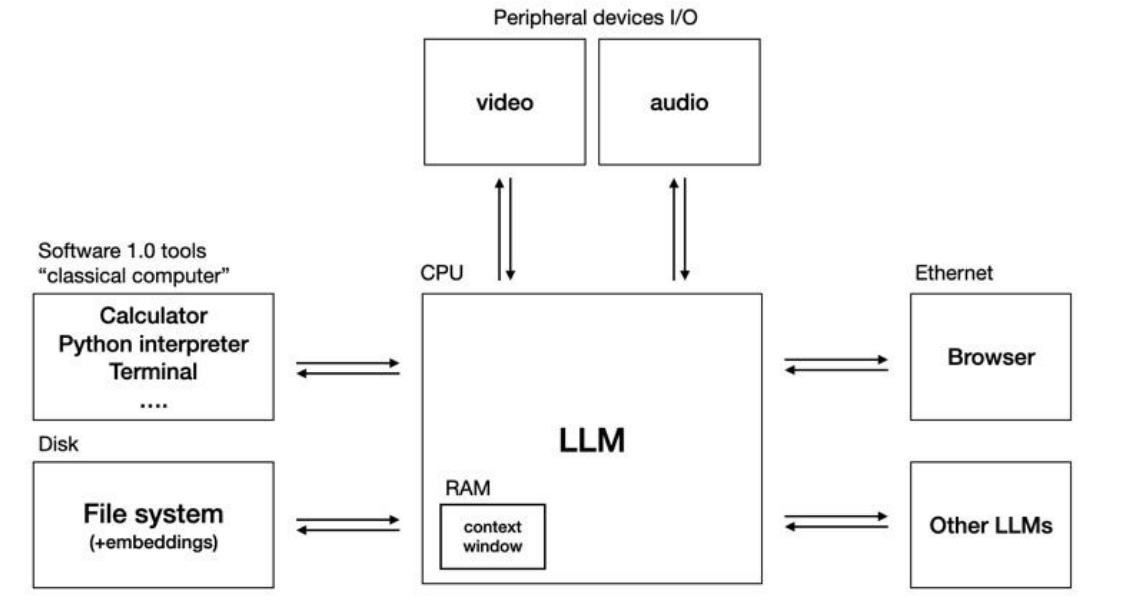
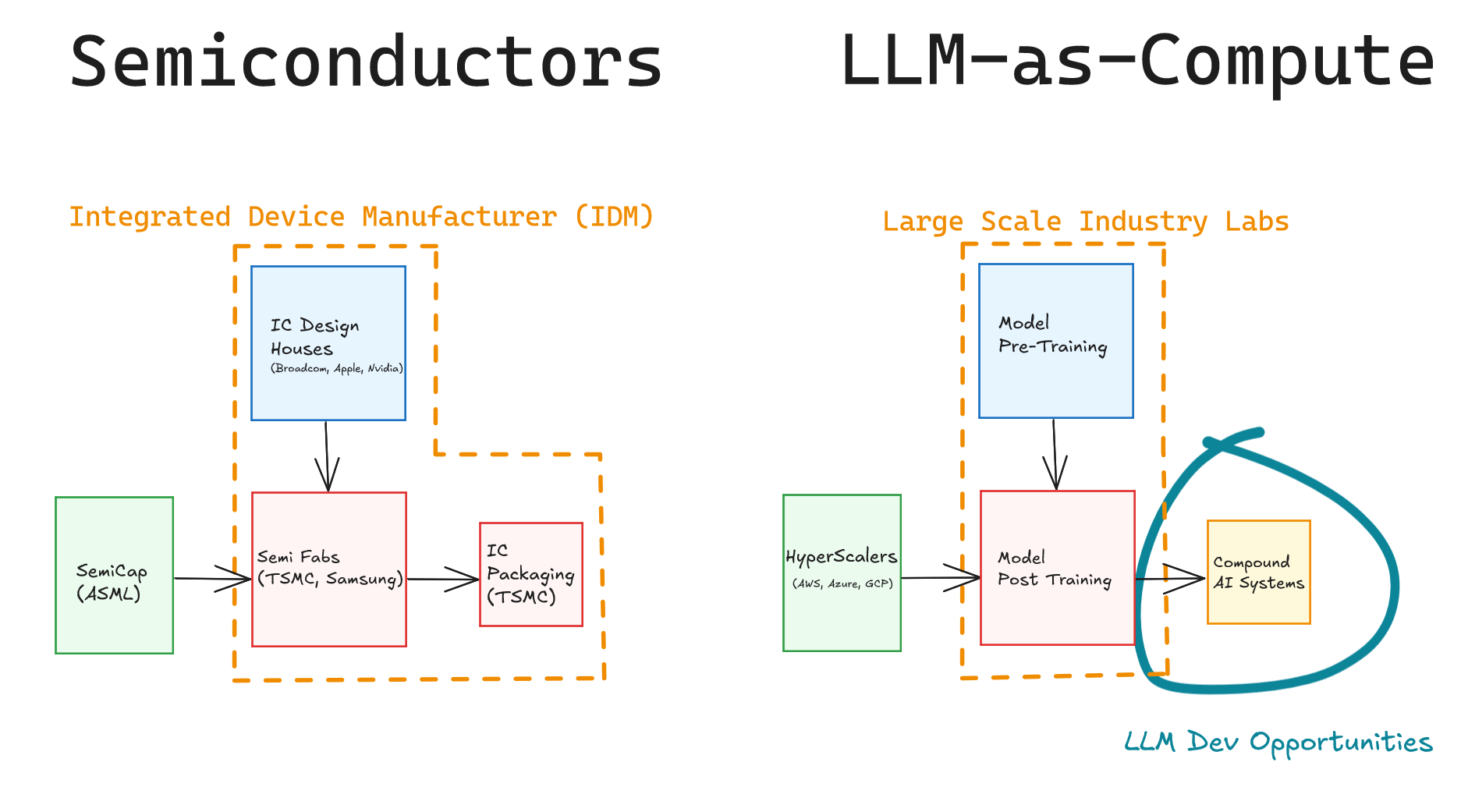
Compound AI System Design vs. Semiconductor Hardware Design
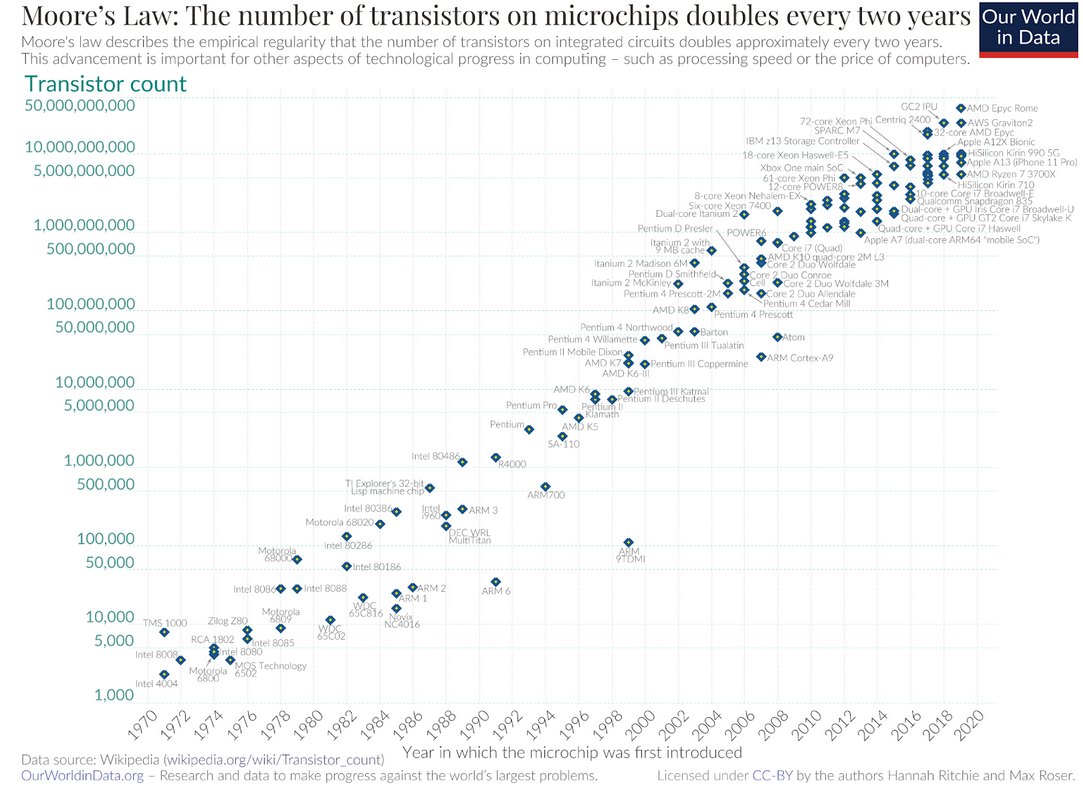
Drawing a parallel with the semiconductor industry, in the early days, logic gates were manually designed using components like PN junctions or CMOS technology. A semiconductor chip is built using logic gates, with each component originally being hand-tuned and optimized by IC design engineers. As Moore’s Law drove miniaturization, circuit complexity increased exponentially. The industry moved from hand-tuning individual gates and components to using electronic design automation (EDA) tools and writing hardware description language (HDL) code to define logic, which was later compiled and synthesized into register transfer logic (RTL). This transition sacrificed some flexibility but allowed for faster iteration.
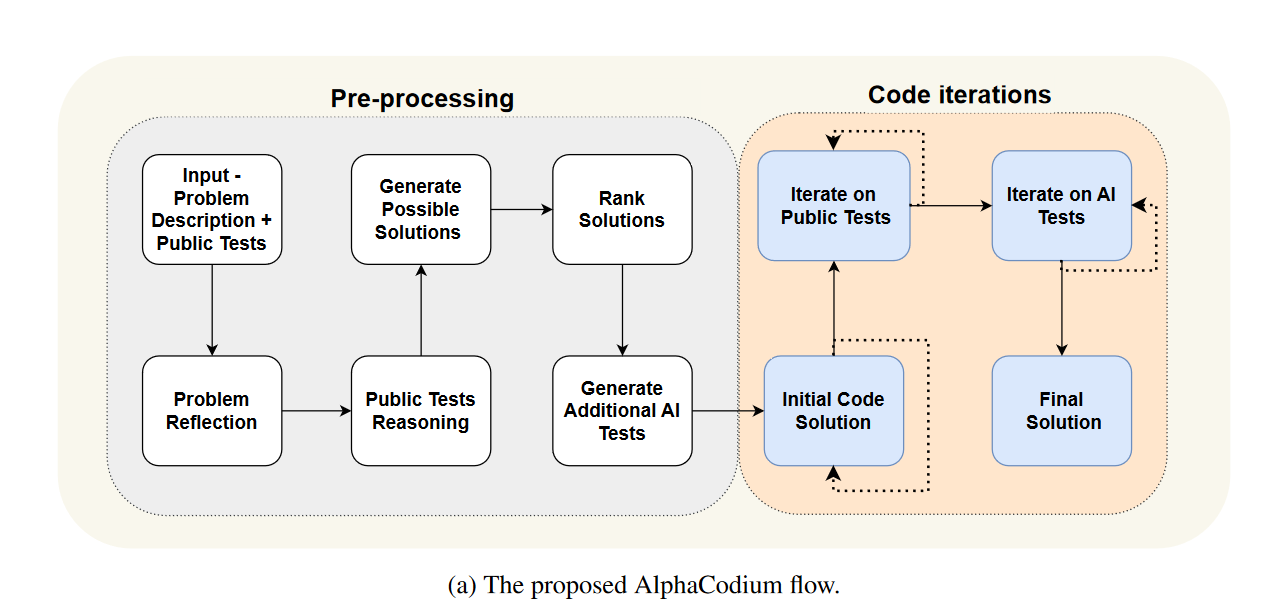
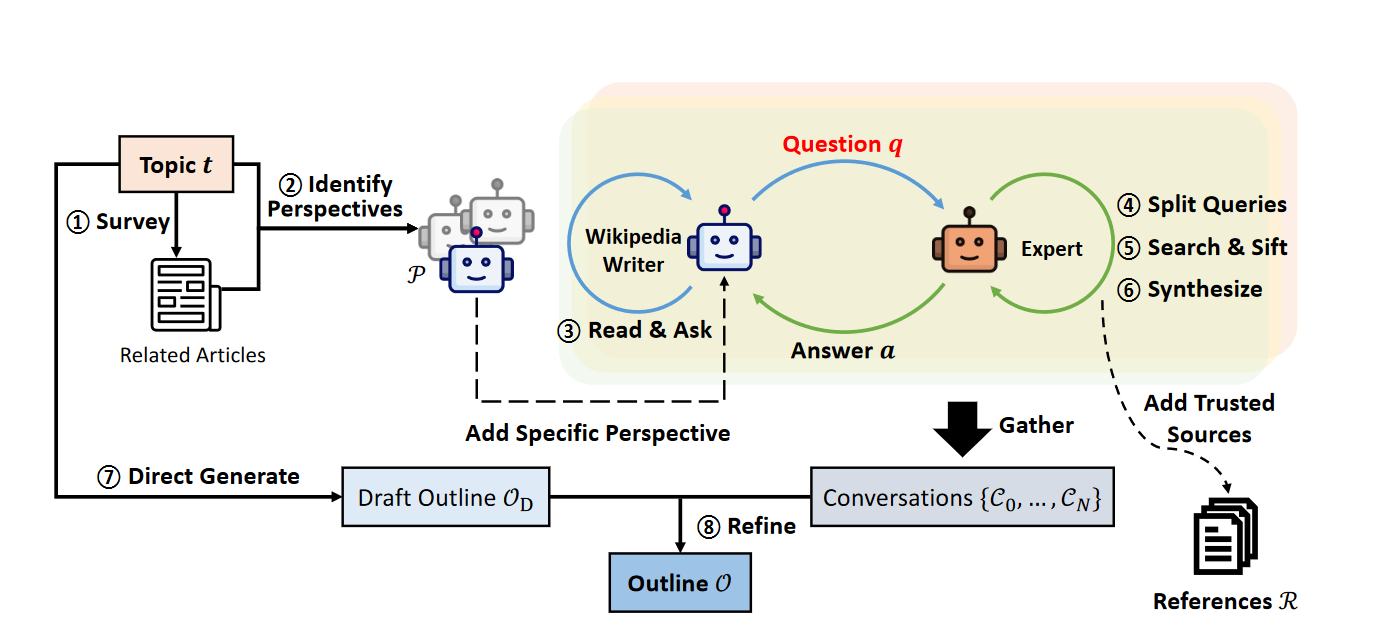
In the current generation of cognitive computing, foundation models serve as the CPUs of compound AI systems. The declarative framework equivalent is LangChain/LangGraph with its LangChain Markup Language (LCEL), while DSPy, with its wide variety of prompt optimizers—such as BootstrapFewShot for optimizing few-shot prompting, and CoPro and MIPRO for optimizing instructions—acts as the compiler and synthesizer. We can quickly sketch out complex workflows and layouts with LangGraph, then synthesize and optimize individual prompts or subsystems. This allows us to scale up to larger systems with reduced complexity. Examples of early compound AI systems include AlphaCodium and Stanford’s STORM system that generates Wikipedia-like articles.
While writing your own markup language and optimizers is possible, it’s not practical from an investment and resource allocation perspective. A home-brewed framework might provide initial velocity, but maintaining it typically requires an immense amount of time and slows development significantly. One good example is the Oracle database, where bug fixes are measured in months, not hours. Again, drawing parallels from the semiconductor industry, companies use Cadence and other off-the-shelf tools because it’s more practical to focus on generating business value than maintaining a LLM systems development framework.
LLM Training vs. Semiconductor Manufacturing
In semiconductors, there are vertically integrated companies called integrated device manufacturers (IDMs), such as Intel, and previously AMD, Texas Instruments, and Motorola. The equivalent of these IDMs in the cognitive computing space are large scale industry labs like OpenAI, Google, and Anthropic. These companies have their own tools and frameworks, having already invested heavily in compute infrastructure to pre-train and post-train their models.
Another type of semiconductor company is asset-lite design houses, meaning they don’t own capital-intensive fabrication plants. Examples include Apple, Broadcom, and Nvidia. The equivalent in compound AI systems is the broader community of companies that utilize off-the-shelf or open-source LLMs to design their own systems, using techniques such as prompt tuning, fine-tuning, or more advanced methods like reasoning. Frameworks like LangGraph and DSPy are especially important for this group.
There are striking parallels between CPUs and transformers as computational models. Both started simpler, with fewer gates or parameters, and gradually expanded in capability. CPUs integrated surrounding chipsets over time, such as the north bridge, math processor, and south bridge. Similarly, transformer models are expanding in capability, integrating additional functionalities such as natural language processing classifiers, reasoning (e.g., OpenAI o1), and encoders (LLM2Vec). The industry is still rapidly evolving, and we will soon define more established abstractions.
Conclusion
History does not repeat itself, but it often rhymes. Whether we accelerate towards cognitive computing or find ourselves in a situation similar to self-driving cars — that always five years away — remains to be seen. The best way to predict the future is to build it, and I would bet on open-source HDLs and optimizers for building LLM systems.
References and Acknowledgements
Special thanks to Shreya Shankar for feedbacks and suggestions.
- LangChain Expression Language (LCEL)
- HackerNews: Ask HN: What’s the largest amount of bad code you have ever seen work?
- Automatic Prompt Optimization with “Gradient Descent” and Beam Search
- Promptbreeder: Self-Referential Self-Improvement Via Prompt Evolution
- DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines
- TextGrad: Automatic “Differentiation” via Text
- Symbolic Prompt Program Search: A Structure-Aware Approach to Efficient Compile-Time Prompt Optimization
- Twitter: Andrej Karpathy
- Youtube: Andrej Karpathy’s Keynote & Winner Pitches at UC Berkeley AI Hackathon 2024 Awards Ceremony
- Feature-Interaction Aware Configuration Prioritization for Configurable Code
- Optimizing Instructions and Demonstrations for Multi-Stage Language Model Programs
- LLM2Vec: Large Language Models Are Secretly Powerful Text Encoders
- OpenAI o1
@article{
leehanchung,
author = {Lee, Hanchung},
title = {Frameworks for LLMs and Compound AI Systems through the Lens of 50 Years of Semiconductor History},
year = {2024},
month = {10},
howpublished = {\url{https://leehanchung.github.io}},
url = {https://leehanchung.github.io/blogs/2024/10/04/llm-as-computer/}
}