Decoding LLM Pricing: The Cost of Input and Output Sequences in Generative AI
Introduction
In the rapidly evolving domain of Large Language Models (LLM), a hot topic has emerged: the pricing models of LLM services. A notable trend is the cost associated with longer output sequences, a seemingly straightforward concept as more extensive outputs demand more inference time. However, a less intuitive aspect is the higher charges for longer input sequences. This blog post aims to demystify the inference mechanics behind this pricing strategy, shedding light on why token-based input sequence length is a crucial factor in LLM cost.
Input Tensor Construction: Prompt Length and Static Batching
The engines driving these models, such as OpenAI’s GPT and Meta’s Llama, are ‘decoder-only’ transformers. These models handle varied input lengths, quantified in tokens, up to a certain threshold. But here’s the catch: the token count of your input doesn’t just determine the response — it also sets the stage for the computational resources required. Longer prompts mean expanded input matrices, increasing the demand on computational resources and thus, the cost.
To optimize inference throughput and cost, static batching is utilized to batch and schedule together inputs of different lengths together before processing.By grouping inputs of disparate lengths, these models can process them more efficiently, akin to the mini-batching technique in training. However, this requires padding shorter prompts to match the longest in the batch.
Consider the following example from Llama’s inference code:
This first code segment determines the size of the input matrix. The larger the matrix, the more GPU logic cores are engaged, consuming more power and potentially reducing speed.
min_prompt_len = min(len(t) for t in prompt_tokens)
max_prompt_len = max(len(t) for t in prompt_tokens)
assert max_prompt_len <= params.max_seq_len
total_len = min(params.max_seq_len, max_gen_len + max_prompt_len)
pad_id = self.tokenizer.pad_id
tokens = torch.full((bsz, total_len), pad_id, dtype=torch.long, device="cuda")
for k, t in enumerate(prompt_tokens):
tokens[k, : len(t)] = torch.tensor(t, dtype=torch.long, device="cuda")
Inference Optimization: Continuous Batching
Once the input tensor has been created, they are sent through LLM for processing. All of the prompts will need to wait until the longest generation prompt to finish.
As an example, the following block from Llama’s orchestrates the forward pass until the completion of every request in the batch.
for cur_pos in range(min_prompt_len, total_len):
logits = self.model.forward(tokens[:, prev_pos:cur_pos], prev_pos)
...
if all(eos_reached):
break
These behaviors inadvertently increasing the computational burden for the shorter ones. It can be visualized as the following graph by Anyscale:
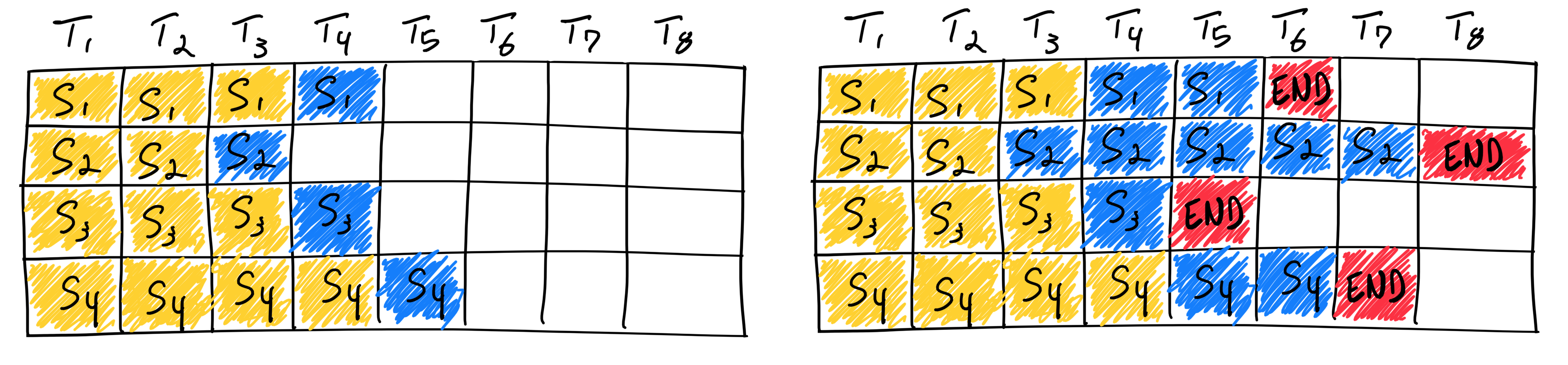
To address this, some have turned to ‘bucket sequence batching’, where requests of similar sequence lengths are grouped, enhancing efficiency. The latest advancement in throughput optimization is ‘Continuous batching’. This scheduling technique allows for the processing of new or shorter requests alongside longer ones, markedly improving inference system throughput.
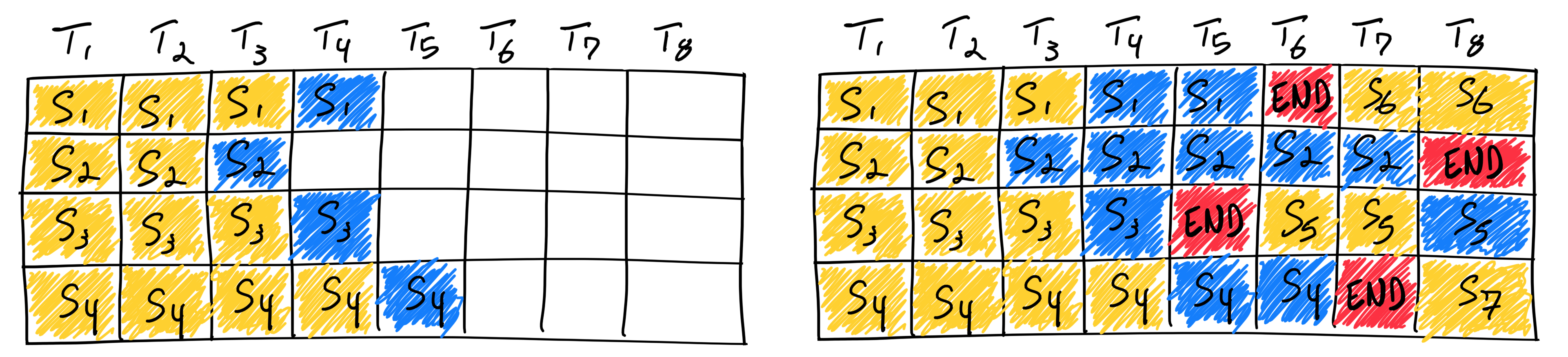
Conclusion: Balancing Efficiency and Cost
Deploying, hosting, and managing LLM inferences at scale is still a prohibitively expensive endeavor. There are more inference througuhtput optimization techniques that’s being developed and hopefully going into production soon.
References
- How continuous batching enables 23x throughput in LLM inference while reducing p50 latency
- Llama 2 Code Base
@article{
leehanchung,
author = {Lee, Hanchung},
title = {Decoding LLM Pricing: The Cost of Input and Output Sequences in Generative AI},
year = {2023},
month = {11},
howpublished = {\url{https://leehanchung.github.io}},
url = {https://leehanchung.github.io/2023-11-13-llm-inference-cost/}
}