Data Leakage in WizardCoder: A LeetCode Reality Check
Introduction
Since the launch of Code Llama on August 24, 2023, there has been a surge in fine-tuning efforts within the pseudo-open-source community. Just two days after the release, Microsoft’s WizardLM Team announced that their fine-tuned WizardCoder 34B, based on Code Llama, achieved a HumanEval score of 73.2 for pass@1. This score surpasses the 2023-03-15 versions of both GPT-4, which scored 67.0, and GPT-3.5, which scored 48.1.
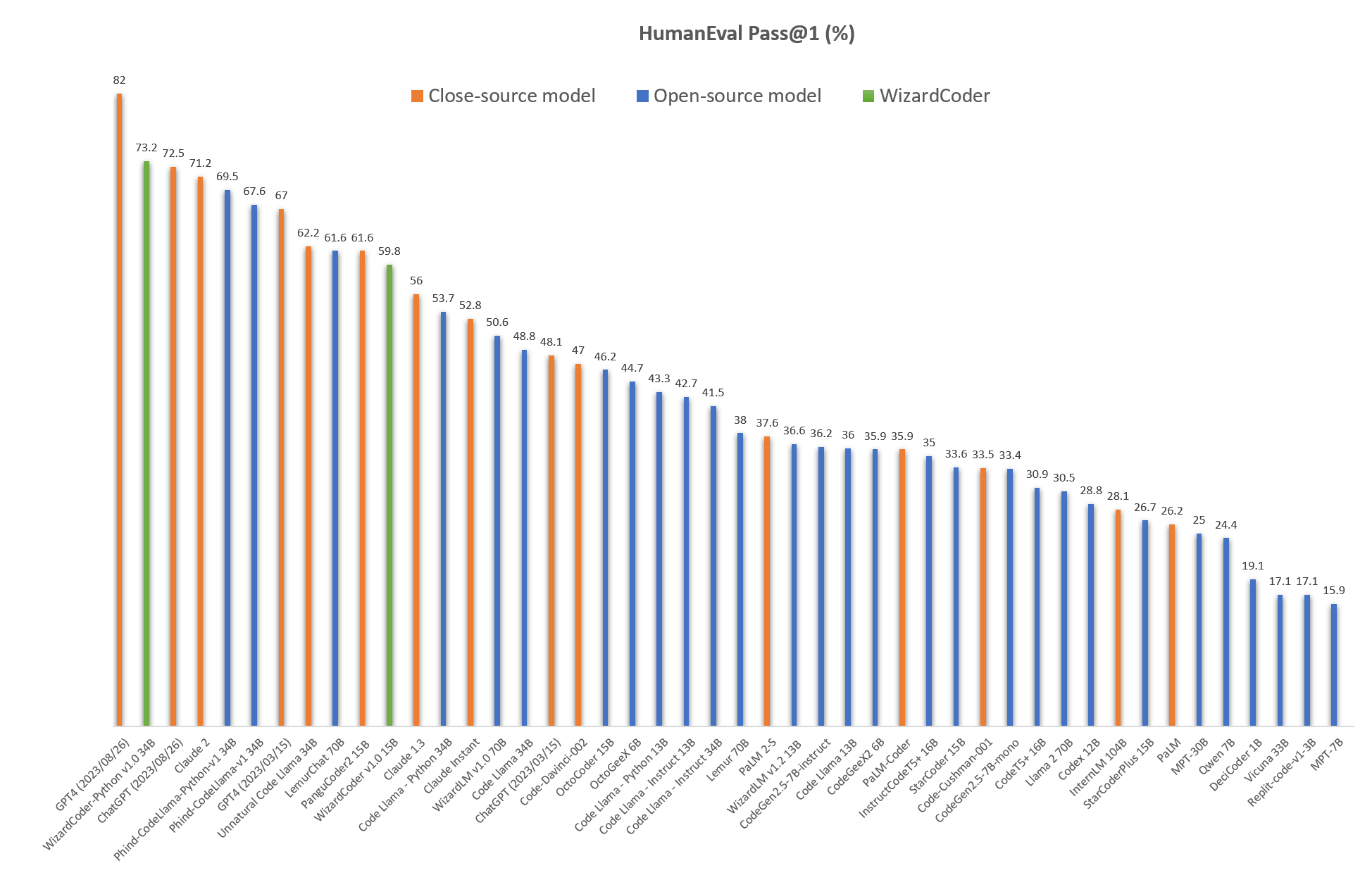
Claim: CodeWizard, a Llama License model, with only 34B parameters, has outperformed on HumanEval vs closed-source models like GPT-3.5 and GPT-4, which have several times more parameters!
Or has it?
Code Generation
Code generation has become a popular focus for LLM fine-tuning within the open-source community, primarily for two reasons: the ease of acquiring or generating data and the simplicity of evaluation without human feedback. Machine learning engineers can assess the quality of generated code through methods such as syntax tree parsing or code execution, thereby eliminating the need for costly evaluations involving experts or model-based approaches.
The current benchmark dataset for code generation is HumanEval, which originates from the paper Evaluating Large Language Models Trained on Code.
HumanEval consists solely of a test dataset featuring 164 coding questions along with their corresponding test codes.
There is no training set, validation set, or train/validation/test split—only a test set.
A sample data entry is as follows:
{
"task_id": "HumanEval/34",
"prompt": "
def unique(l: list):
"""Return sorted unique elements in a list
>>> unique([5, 3, 5, 2, 3, 3, 9, 0, 123])
[0, 2, 3, 5, 9, 123]
"""
",
"entry_point": "unique",
"canonical_solution": " return sorted(list(set(l)))
",
"test": "
METADATA = {}
def check(candidate):
assert candidate([5, 3, 5, 2, 3, 3, 9, 0, 123]) == [0, 2, 3, 5, 9, 123]
"
}
Evol-Instruct
The WizardLM team pinoreered the Evol-Instruct algorithm, which operates as follows:
- Begin with an initial set of instruction fine-tuning data, denoted as $D^{(0)}$.
- Use LLM to augment this data with more complex prompts, expanding both in breadth and depth.
- Use LLM to generate responses to these prompts.
- Use LLM and heuristics to filter out poorly generated responses.
- Add the newly generated data, $D^{(1)}$, to the existing instruction fine-tuning data collection.
- Iterate the above steps on the last evolution data $D^{(n-1)}$ for M evolutions.
- Fine-tune the model using the complete instruction fine-tuning data collection.
The process can be visualized as follows:
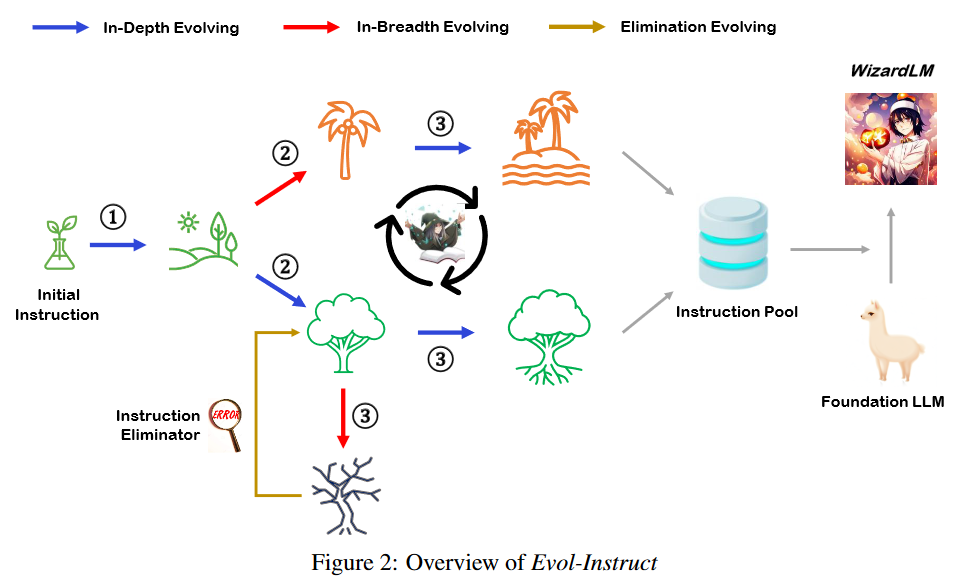
This novel self-supervised approach for augmenting instruction fine-tuning data has yielded a series of high-performing, fine-tuned, general-purpose models from the WizardLM team.
WizardCoder
The data evolution algorithm has also been applied to code generation in the pape WizardCoder — but with a significant caveat.

WizardCoder intentionally evaluates data generation on the test set at every iteration.
The WizardCoder training process iteratively probes the HumanEval dataset at each stage of data evolution.
This constitutes a classic example of feature leakage. The features and characteristics of the HumanEval benchmarks are probed during every iteration of the Evol-Instruct data generation process. WizardCoder iteratively fine-tunes on the generated data, evaluates performance on HumanEval, and repeats the generation/evaluation process until the pass@1 score peaks on HumanEval.
This is intentional data leakage, distinct from inadvertently including evaluation data from a large corpus of books and internet pre-training data comprising billions of tokens.
As a result, the HumanEval test score becomes obsolete and cannot serve as a valid point of comparison.
Coding Ability Evaluation
The most effective evaluation of coding ability should focus on real-world tasks, such as those found on LeetCode, which many tech companies use to assess engineering candidates. While a substantial number of easy and medium LeetCode problems have been leaked online, a significant portion of proprietary questions remains unavailable to the public.
Owen Colegrove has invested considerable effort in rigorously evaluating models using LeetCode Sparks and LeetCode 100 as part of his Zero Shot Replication Framework. The results are as follows:
| Category | gpt-3.5-turbo-0613 | claude-2 | gpt-4-0613 | code-llama-34b | wizard-coder-34b |
|---|---|---|---|---|---|
| Standard Bench | |||||
| HumanEval | 61.5 | 65.2 | 84.1 | 56.7 | 69.5 |
| HumanEval+ | 54.2 | 54.9 | 74.4 | 48.2 | 60.3 |
| LeetCodeSparks | |||||
| Easy | 76.2 | 52.4 | 61.2 | 33.3 | 42.9 |
| Medium | 22.0 | 9.8 | 31.7 | 2.4 | 12.2 |
| Hard | 0.0 | 0.0 | 13.6 | 0.0 | 0.0 |
| LeetCode100 | |||||
| Easy | 80.0 | 73.0 | 88.0 | 53.0 | 68.0 |
| Medium | 16.0 | 16.0 | 21.0 | 3.0 | 9.0 |
| Hard | 3.0 | 2.0 | 6.0 | 0.0 | 0.0 |
Conclusion
From the evaluation above, we can reach two conclusions:
- The Code Evol-Instruct algorithm yields a notable improvement in WizardCoder-34B compared to its base model, Code Llama-34B, particularly on LeetCode Medium problems.
- Open-source models still lag behind closed-source models that are several times their size, and the gap is significant.
References
- Ikka on Twitter
- Evaluating Large Language Models Trained on Code.
- WizardCoder: Empowering Code Large Language Models with Evol-Instruct
- WizardLM: Empowering Large Language Models to Follow Complex Instructions
- Owen Colegrove: Zero Shot Replication Framework
@article{
leehanchung,
author = {Lee, Hanchung},
title = {Data Leakage in WizardCoder: A LeetCode Reality Check},
year = {2023},
month = {9},
howpublished = {\url{https://leehanchung.github.io}},
url = {https://leehanchung.github.io/2023-09-01-data-leakage-in-wizard-coder/}
}