Serve Keras Model with Tensorflow Serving
After spending precious time and compute training a model and tuning hyperparameter, a deep learning model is born. Now what? Life is not always a Kaggle competition where merely submitting inferenced results suffice.
Time to deploy the model into production push your new born baby model off the cliff to see if it flies.
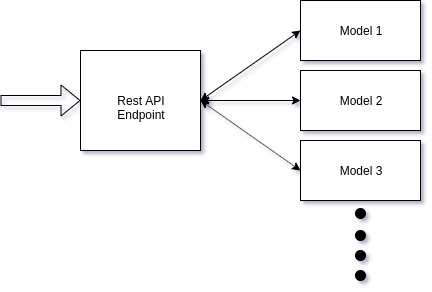
Endpoint Architecture
A full blown REST API Endpoint with ingesting, preprocessing, model inferencing, and post processing steps in production will have surprisingly multiple bottlenecks in the process that will fail at load testing time. For example, the ingesting step will be I/O bound, the inferecing step will be bound by model inference speeds, and the post processing step might be I/O bound as well.
A better engineered approach is to modularize and carve out the models endpoints from the REST API Endpoint server that connects to the frontend. REST API endpoint developement can now be separate from model development and now we can use higher throughput model serving frameworks such as Tensorflow Serving. At the same time, it allows us to serve multiple models at the same time.
Preparing Keras Model for Tensorflow Serving
Before we can serve Keras model with Tensorflow Serving, we need to convert the model into a servable format.
WARNING: make sure you have a version number at the end of the output_directory, e.g., resnet/1, your_model_name/1. Both Tensorflow Serving and Tensorflow saved model loading requires the 1 (version number) to find the saved_model.pb protobuf file and weights.
WARNING: Some legacy blog post uses tf.saved_model.simple_save(). THIS FUNCTION IS DEPRECATED in Tensorflow 2.x according to official documentation..
# Load the Keras Model
model = tf.keras.models.load_model(model_name)
# Save the model in a servable format
tf.saved_model.save(model, output_directory)
Now, the model can be loaded and used for inference as follows:
# load model
loaded_model = tf.saved_model.load(output_directory)
Model Verification
The model is now in a frozen graph, so we have to pass the input variable X into the graph to get the output using tf.constant() as follows:
# get the output of the graph
infer_key = list(loaded_model.signatures.keys())
infer = loaded.signaturess[infer_key[0]]
# print the output layer for information
print(infer.structured_outputs)
# Set X as a tf.constant and input to the frozen graph and find the output out
out = infer(tf.constant(X))
For sanity checking, we can run inference using both Keras and the converted Tensorflow servable model and make sure the ouptut is the same.
One other way to check the servable model parameters is to use the saved_model_cli command from Tensorflow.
saved_model_cli show --dir {output_directory}/{version} --tag_set serve --signature-def serving_default
Tensorflow Serving, Locally
We can now use Tensorflow Serving to serve the model locally using tensorflow_model_server. In case the command has not been installed in the system, it can be installed using apt-get install tensorflow_model_server. We found it easier to troubleshoot than using tensorflow/serving Docker image.
NOTE: Tensorflow Serving serves gRPC usingi port 8500 and serves REST API using port 8501. It would be a good idea to use the defaults.
tensorflow_model_server --model_base_path={absolute/path/to/the/model} --rest_api_port=8501 --model_name={name_your_model_here}
Now, you should see something like:
2019-12-18 HH:MM:SS.SSSSSS I tensorflow_serving/model_servers/server.cc:353] Running gRPC ModelServer at 0.0.0.0:8500 ...
2019-12-18 HH:MM:SS.SSSSSS I tensorflow_serving/model_servers/server.cc:373] Exporting HTTP/REST API at:localhost:8501 ...
Sending Requests to Tensorflow Serving Endpoint
To send a request to the endpoint, we will use our beloved Python request module. First we would have to construct a preprocessed input JSON in the {"instances": {input}} format and POST it to the endpoint. The output will be coming back, again, in JSON format in the 'predictions' field.
# Assume input variable X
predict_request = f'{{"instances" : {X}}}'
# POST input request JSON to the endpoint
response = requests.post(SERVER_URL, data=predict_request)
response.raise_for_status()
prediction = response.json()['predictions']
Alternatively, when the expected inputs is small compare to, say, a (1, 255, 255, 3) image array, cURL is always here.
curl +X POST "http://localhost:8501" -d '{"instances": [0, 1, 2, 3, 4, 5]}'
Viola, now we have the response from the Tensorflow Servings endpoint. As a reference, we have implemented this architecture in our Memefly Project REST API Endpoint.
Next up, we will try to package model files into a Tensorflow Servings Docker image, store it in Amazon ECR container registry, and deploy it to Amazon Sagemaker.