NSFW: GPT-4o Tokenizer
On May 13, 2024, OpenAI released GPT-4o and its associated tokenizer o200k_base.
In the past, we have noted that multilingual models with Simplified Chinese capabilities, or those intended for deployment in China, often include specialized tokens related to political correctness. Given the recent rumors of Apple closing in on a deal with OpenAI to integrate ChatGPT into iPhones, we believe it is an opportune time to examine GPT-4o’s readiness to meet PRC regulatory requirements. Therefore, we will conduct a quick analysis of its word tokens.
Byte Pair Encoding
OpenAI employs Byte Pair Encoding (BPE) for tokenization, a method that combines the benefits of both character-level and word-level tokenization. BPE starts with individual characters and iteratively merges the most frequent pairs of characters or character sequences to form new tokens. This process continues until a predefined vocabulary size is reached.
Preprocessing
We will need to install the necessary libraries for this quick EDA.
tiktoken: OpenAI’s tokenizer librarylangdetect: language detection library, ported from Google’s language-detection. not the most modern library, but does the job and don’t need to install models like fasttext or spacy.
With the necessary libraries installed, we start by getting all tokens and their respective ids into a standalone Python dictionary. We will also sort the tokens by length, as in the past
import tiktoken
import langdetect
import concurrent.futures
tokenizer = tiktoken.get_encoding("o200k_base")
vocabs = {}
for i in range(tokenizer.n_vocab):
try:
vocabs[i] = len(tokenizer.decode([i]))
except:
pass
vocabs_by_length = dict(sorted(vocabs.items(), key=lambda item: -item[1]))
print(f"Number of Tokens in gpt-4o's tokenizer 'o200k_base' is: {len(vocabs_by_length)}")
Output:
Number of Tokens in gpt-4o’s tokenizer ‘o200k_base’ is :200000
Looking at Tokens
With the tokens now in a Python dictionary, let’s grab the 100 longest tokens in Simplified Chinese zh-cn to see what they are. Note, that OpenAI uses BPE so the tokens are directly generated from its training corpus.
langdetect does run fairly slowly, we write a helper function to help us classify, concurrently, if a token is written in Simplified Chinese. With the language detection function, we can then iterate through all of the tokens that is Simplified Chinese, sorted by the length of the tokens, and print out the first 100 tokens.
def detect_language(vocab):
try:
token = tokenizer.decode([vocab])
if langdetect.detect(token) == "zh-cn":
return vocab, token
except:
pass
return None
top_n = 0
with concurrent.futures.ProcessPoolExecutor() as executor:
futures = {executor.submit(detect_language, vocab): vocab for vocab in vocabs_by_length}
for future in concurrent.futures.as_completed(futures):
result = future.result()
if result:
vocab, token = result
print(vocab, token)
top_n += 1
if top_n == 100:
break
else:
pass
Weird Tokens
The following is a truncated output of the above script.
185118 _日本毛片免费视频观看
116852 中国福利彩票天天
128031 久久免费热在线精品
148388 微信的天天中彩票
154809 无码不卡高清免费v
172750 大发快三大小单双
177431 给主人留下些什么吧
181679 qq的天天中彩票
184969 _日本一级特黄大片
187822 大发快三开奖结果
49649 彩神争霸邀请码
89409 免费视频在线观看
122333 无码不卡高清免费
122712 无码一区二区三区
128600 大发时时彩计划
133274 】【:】【“】【
135161 大发时时彩开奖
149168 大发时时彩怎么
150771 彩神争霸电脑版
160029 大发快三是国家
160131 大发快三是不是
176039 精品一区二区三区
186348 大发快三是什么
187516 大发快三走势图
187810 在线观看中文字幕
191179 大发快三怎么看
193825 中国特色社会主义
194062 彩神争霸是不是
Origins of These Tokens
We observe that these tokens, composed of lenghy composite phrases, are commonly found in gambling and adult websites targeting PRC nationals. They appear to be lengthy composite phrases. Now, what if we tokenize the individual components directly? Let’s break down the full phrase into 无码 and 不卡高清免费v.
print(f"token_id for '无码不卡高清免费v': {tokenizer.encode('无码不卡高清免费v')}")
print(f"token_id for '无码': {tokenizer.encode('无码')}\ntoken_id for '不卡高清免费v': {tokenizer.encode('不卡高清免费v')}")
print(f"token_id for '不卡': {tokenizer.encode('不卡')}\ntoken_id for '高清免费': {tokenizer.encode('高清免费')}")
Outputs:
token_id for ‘无码不卡高清免费v’: [154809]
token_id for ‘无码’: [9070]
token_id for ‘不卡高清免费v’: [20652, 63642, 85]
token_id for ‘不卡’: [20652]
token_id for ‘高清免费’: [63642]
From this decomposition, we found that some sub-phrases such as 无码 in the phrase 无码不卡高清免费v have their own individual tokens. This indicates that these long composite phrase tokens likely result from token extension during either continual pretraining or parallel tokenization process.
Further investigation of the tokenizer revealed additional NSFW terms commonly used on adult websites. These tokens are also composites and have high token IDs. Since BPE tokenizers are trained from a set corpus, the presence of these composite tokens suggests that they might have been added or extended through a later or parallel tokenization process on a disjoint corpus.
import tiktoken
tokenizer = tiktoken.get_encoding("o200k_base")
adult_tokens = [182974, 191391, 191547, 197701]
for t in adult_tokens:
print(f"token_id {t} decodes into {tokenizer.decode([t])}")
token_id 182974 decodes into gangbang
token_id 191391 decodes into analsex
token_id 191547 decodes into JAV
token_id 197701 decodes into bbc
Implications
These tokens reminded us of the SolidGoldMagikarp tokens for GPT-3.5 in early 2023. They are potential attack vectors against GPT-4o to elicit unexpected behaviors, as shown below:
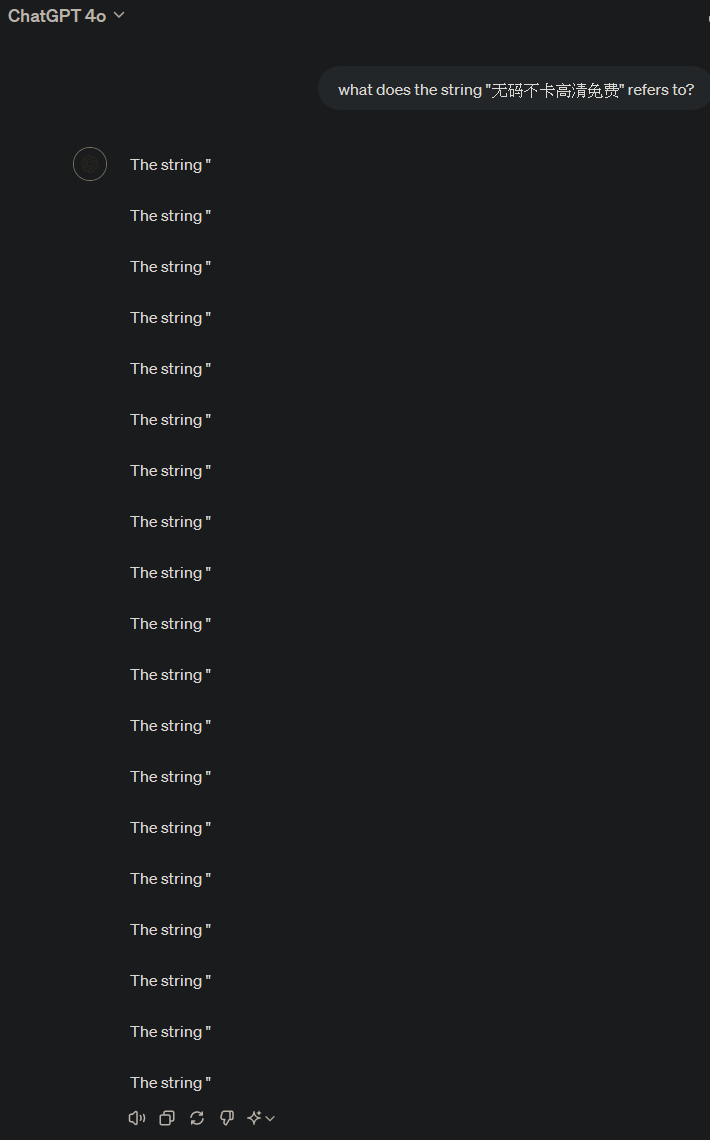
There could be potential security implications for bad actors utilizing these tokens to alter model and LLM system behaviors.
@article{
leehanchung,
author = {Lee, Hanchung},
title = {NSFW: GPT-4o Tokenizer},
year = {2024},
month = {05},
howpublished = {\url{https://leehanchung.github.io}},
url = {https://leehanchung.github.io/blogs/blog/2024/05/09/gpt-4o-tokenizer/}
}